How to Use Advanced Job Settings
Parameters and Secrets
It is common to train models with different parameters. OpenPAI supports parameter definition and reference, which provides a flexible way of training and comparing models. You can define your parameters in the Parameters section and reference them by using <% $parameters.paramKey %> in your commands. For example, the following picture shows how to define the Quick Start job using a stepNum parameter.
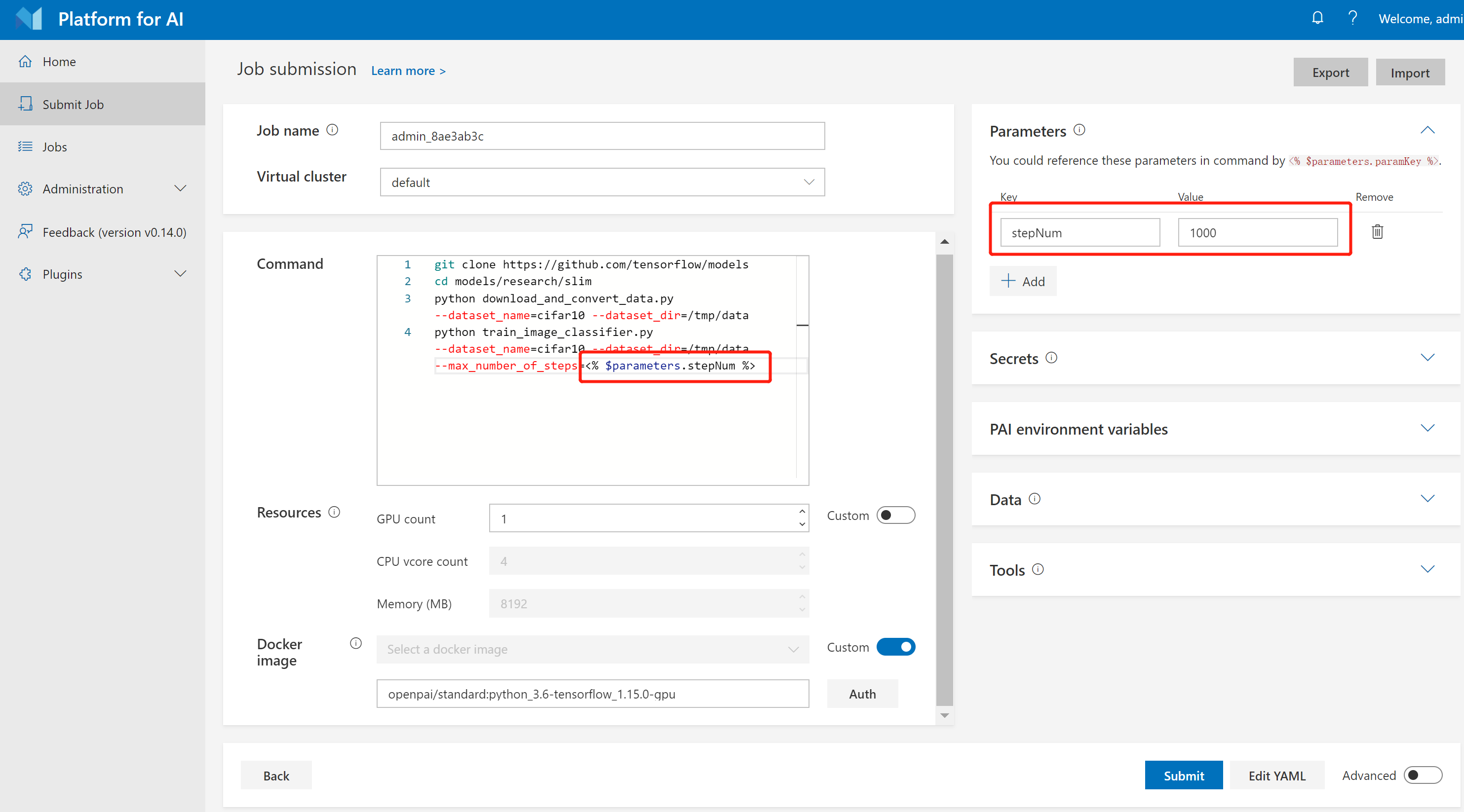
You can define batch size, learning rate, or whatever you want as parameters to accelerate your job submission.
In some cases, it is desired to define some secret messages such as passwords, tokens, etc. You can use the Secrets section for the definition. The usage is the same as parameters except that secrets will not be displayed or recorded.
Multiple Task Roles
If you use the Distributed button to submit jobs, then you can add different task roles for your job.
What is a task role? For single server jobs, there is only one task role. For distributed jobs, there may be multiple task roles. For example, when TensorFlow is used to run distributed jobs, it has two roles, including the parameter server and the worker.
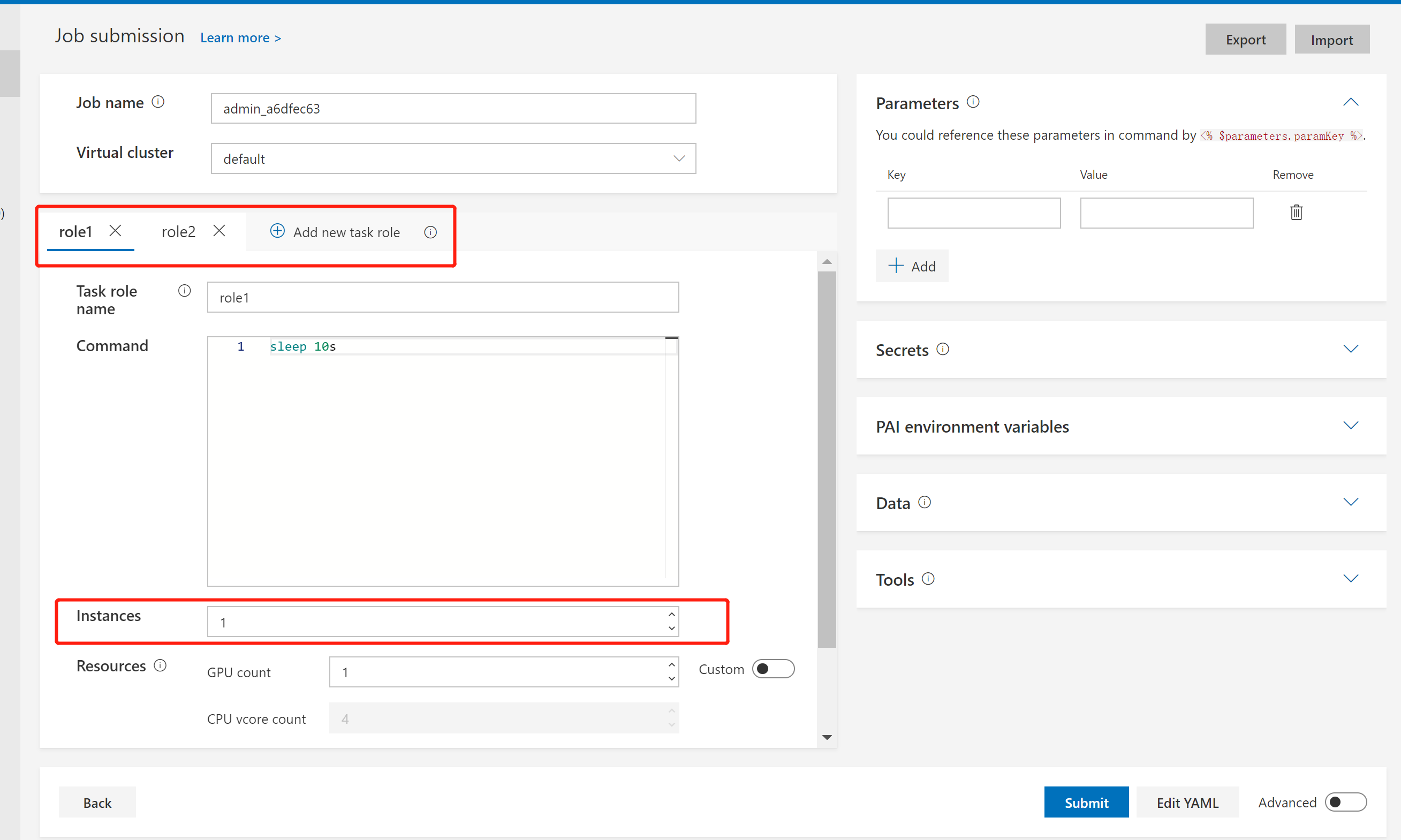
Instances in the following picture is the number of instances of certain task roles. In distributed jobs, it depends on how many instances are needed for a task role. For example, if you set instances to 8 for a TensorFlow worker task role, it means there should be 8 Docker containers for the worker role.
Environmental Variables and Port Reservation
In a distributed job, one task might communicate with others (When we say task, we mean a single instance of a task role). So a task needs to be aware of other tasks' runtime information such as IP, port, etc. The system exposes such runtime information as environment variables to each task's Docker container. For mutual communication, users can write code in the container to access those runtime environment variables.
Below we show a complete list of environment variables accessible in a Docker container:
| Category | Environment Variable Name | Description |
|---|---|---|
| Job level | PAI_JOB_NAME | jobName in config file |
| PAI_USER_NAME | User who submit the job | |
| PAI_DEFAULT_FS_URI | Default file system uri in PAI | |
| Task role level | PAI_TASK_ROLE_COUNT | Total task roles' number in config file |
| PAI_TASK_ROLE_LIST | Comma separated all task role names in config file | |
PAI_TASK_ROLE_TASK_COUNT_$taskRole |
Task count of the task role | |
PAI_HOST_IP_$taskRole_$taskIndex |
The host IP for taskIndex task in taskRole |
|
PAI_PORT_LIST_$taskRole_$taskIndex_$portType |
The $portType port list for taskIndex task in taskRole |
|
PAI_RESOURCE_$taskRole |
Resource requirement for the task role in "gpuNumber,cpuNumber,memMB,shmMB" format | |
PAI_MIN_FAILED_TASK_COUNT_$taskRole |
taskRole.minFailedTaskCount of the task role |
|
PAI_MIN_SUCCEEDED_TASK_COUNT_$taskRole |
taskRole.minSucceededTaskCount of the task role |
|
| Current task role | PAI_CURRENT_TASK_ROLE_NAME | taskRole.name of current task role |
| Current task | PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX | Index of current task in current task role, starting from 0 |
Some environmental variables are in association with ports. In OpenPAI, you can reserve ports for each task in advanced settings, as shown in the image below:
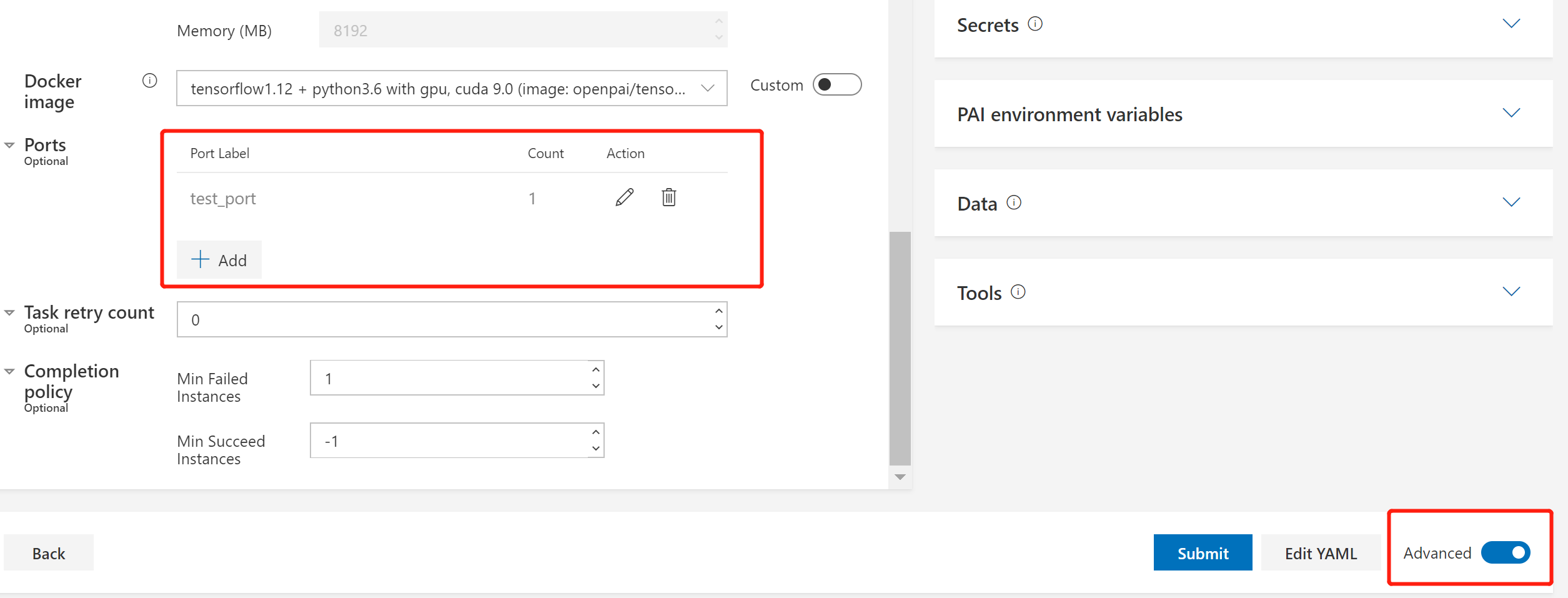
The ports you reserved are available in environmental variables like PAI_PORT_LIST_$taskRole_$taskIndex_$portLabel, where $taskIndex means the instance index of that task role.
For a detailed summary, there are two ways to reference a declared port (list):
- use Indirection supported by
bashas below
MY_PORT="PAI_PORT_LIST_${PAI_CURRENT_TASK_ROLE_NAME}_${PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX}_<port-label>"
PORT=${!MY_PORT}
Note that you need to use $PAI_CURRENT_TASK_ROLE_NAME and $PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX
- use a to-be-deprecated environmental variable to get port (list) in current container like
PAI_CONTAINER_HOST_<port-label>_PORT_LIST
Job Exit Spec, Retry Policy, and Completion Policy
There are always different kinds of errors in jobs. In OpenPAI, errors are classified into 3 categories automatically:
- Transient Error: This kind of error is considered transient. There is a high chance to bypass it through a retry.
- Permanent Error: This kind of error is considered permanent. Retries may not help.
- Unknown Error: Errors besides transient error and permanent error.
In jobs, transient errors will be always retried, and permanent errors will never be retried. If an unknown error happens, PAI will retry the job according to user settings. To set a retry policy and completion policy for your job, please toggle the Advanced mode, as shown in the following image:
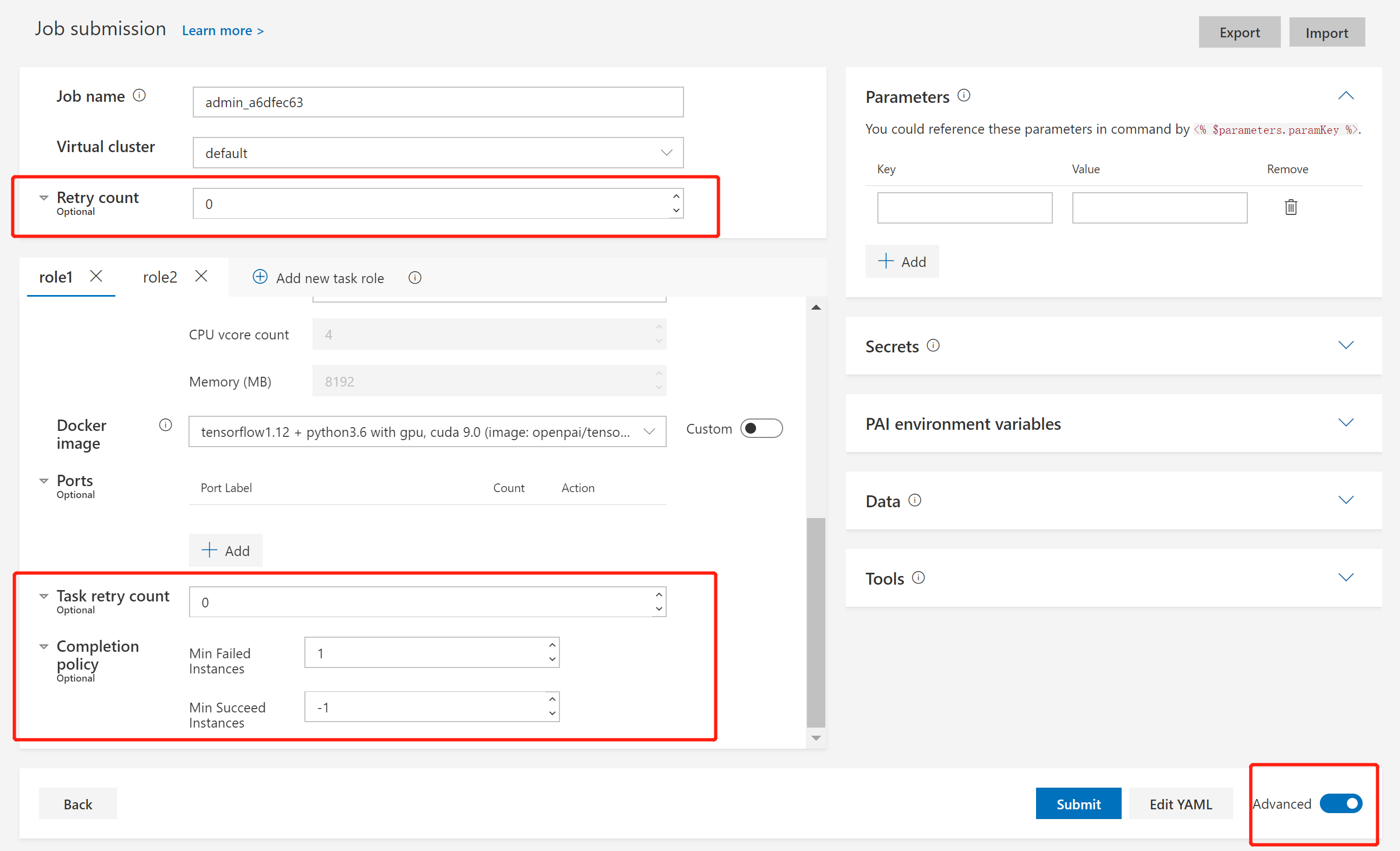
Here we have 3 settings: Retry count, Task retry count, and Completion policy. To explain them, we should be aware that a job is made up of multiple tasks. One task stands for a single instance in a task role. Task retry count is used for task-level retry. Retry count and Completion policy are used for job-level retry.
Firstly, let's look at Retry count and Completion policy.
In Completion policy, there are settings for Min Failed Instances and Min Succeed Instances. Min Failed Instances means the number of failed tasks to fail the entire job. It should be -1 or no less than 1. If it is set to -1, the job will always succeed regardless of any task failure. The default value is 1, which means 1 failed task will cause an entire job failure. Min Succeed Instances means the number of succeeded tasks to succeed the entire job. It should be -1 or no less than 1. If it is set to -1, the job will only succeed until all tasks are completed and Min Failed Instances is not triggered. The default value is -1.
If a job: 1. doesn't succeed after it satisfies Completion policy, 2. fails with an unknown error, and 3. has a Retry count larger than 0, the whole job will be retried. Set Retry count to a larger number if you need more retries.
Finally, for Task retry count, it is the maximum retry number for a single task. A special notice is that this setting won't work unless you set extras.gangAllocation to false in the job protocol.
Job Protocol, Export and Import Jobs
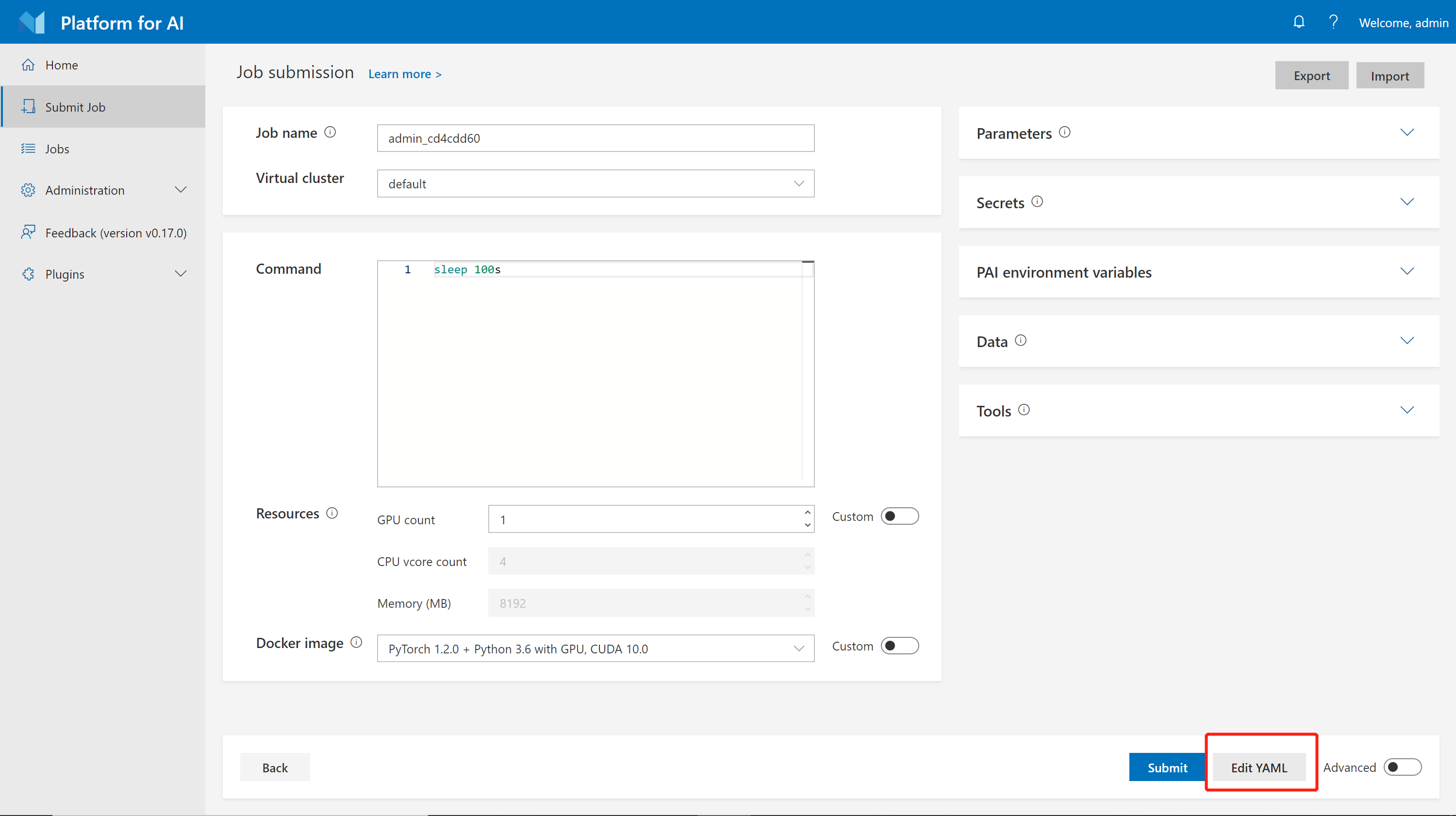
In OpenPAI, all jobs are represented by YAML, a markup language. You can click the button Edit YAML to edit the YAML definition directly:
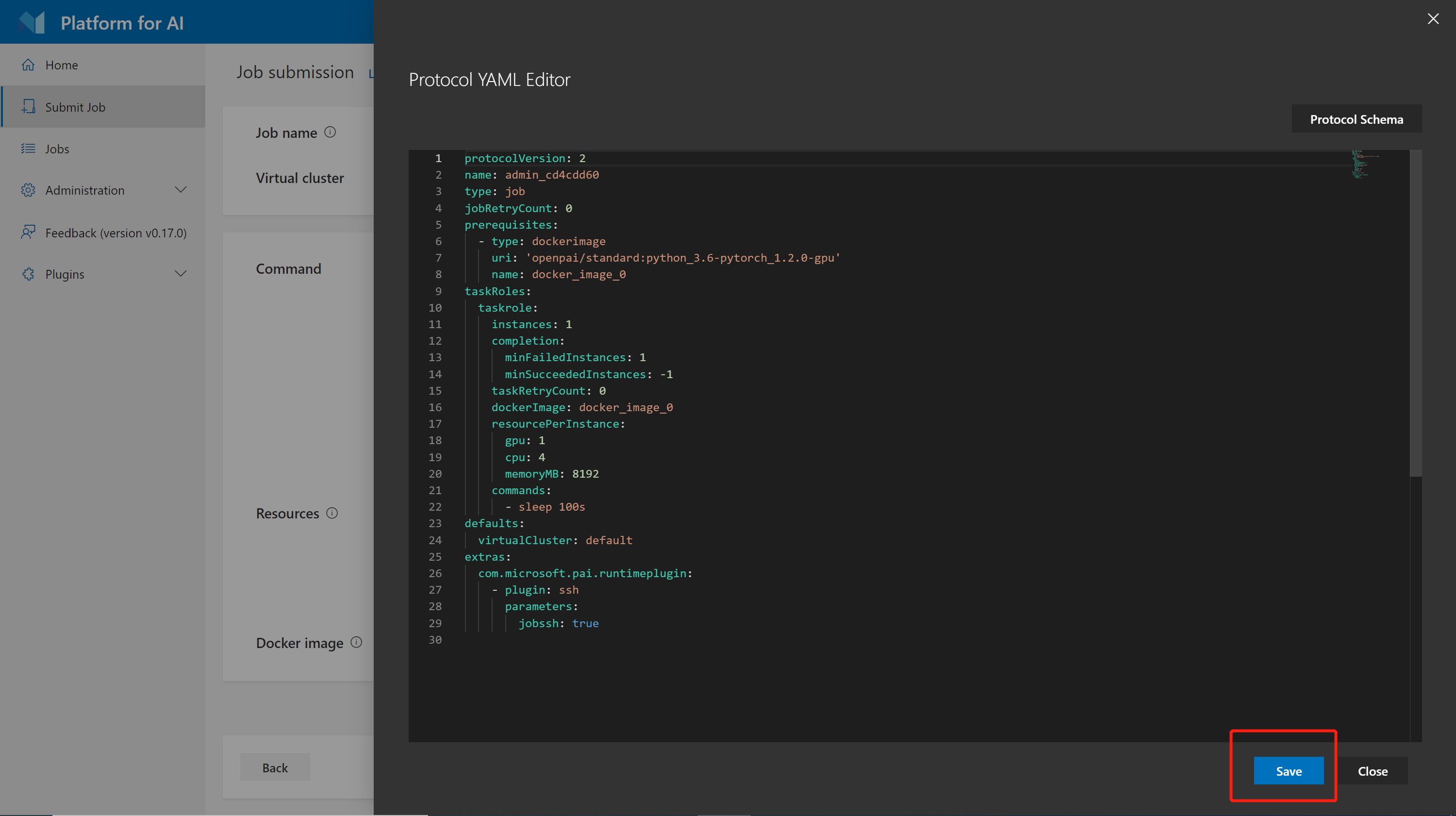
Use the Save button to apply any changes:
You can also export and import YAML files using the Export and Import buttons.
To see a full reference of job protocol, please check job protocol.
Use Prerequisites
OpenPAI protocol support users to specify different types of prerequisites (e.g. dockerimage, data, and script) and then reference them in each task role. We consider prerequisites as sharable parts in the job protocol. For example, one dataset can be defined as a prerequisite, and can be used by multiple jobs.
Here's one example to use prerequisites:
protocolVersion: 2
name: test_prerequisites
type: job
jobRetryCount: 0
prerequisites:
- type: script
name: install-git
plugin: com.microsoft.pai.runtimeplugin.cmd
callbacks:
- event: taskStarts
commands:
- apt update
- apt install -y git
- type: data
name: covid-19-data
plugin: com.microsoft.pai.runtimeplugin.cmd
callbacks:
- event: taskStarts
commands:
- mkdir -p /dataset/covid-19
- >-
git clone https://github.com/ieee8023/covid-chestxray-dataset.git
/dataset/covid-19
- type: dockerimage
uri: 'ubuntu:18.04'
name: docker_image_0
taskRoles:
taskrole:
instances: 1
completion:
minFailedInstances: 1
taskRetryCount: 0
prerequisites:
- install-git
- covid-19-data
dockerImage: docker_image_0
resourcePerInstance:
gpu: 1
cpu: 3
memoryMB: 29065
commands:
- ls -la /dataset/covid-19
defaults:
virtualCluster: default
extras:
com.microsoft.pai.runtimeplugin:
- plugin: ssh
parameters:
jobssh: true
In the top-level prerequisites field, we define two prerequisites: one is install-git, and the other is covid-19-data. covid-19-data downloads a dataset to the folder /dataset/covid-19. install-git is a prerequisites to install git.
In the taskRoles.taskrole.prerequisites field, we reference the two prerequisites in such order: 1. install-git 2. covid-19-data. Thus install-git will be executed before covid-19-data when the corresponding task starts. After the two prerequisites are executed, the user will be able to use the dataset in /dataset/covid-19.
The full spec is as follows:
prerequisites:
- name: string # required, unique name to find the prerequisite (from local or marketplace)
type: "dockerimage | script | data | output" # for survey purpose (except dockerimage), useless for backend
plugin: string # optional, the executor to handle current prerequisite; only support com.microsoft.pai.runtimeplugin.cmd for now
require: [] # optional, other prerequisites on which the current one depends; will be parsed by backend automatically
failurePolicy: "ignore | fail" # optional, same default as runtime plugin
uri: string | array # optional, for backward compatibility
# plugin-specific properties
# Other parameters for the plugin can be inserted here.
# For example, "callbacks" is a parameter for com.microsoft.pai.runtimeplugin.cmd.
taskRoles:
taskrole:
prerequisites: # specified prerequisites will be used in the task role.
- prerequisite-1 # on taskStarts, will execute in order
- prerequisite-2 # on taskSucceeds, will execute in reverse order
In the future, OpenPAI will provide a convenient way to manage and share different kinds of prerequisites among cluster users.
Job Status Change Notification
Job Status Change Notification is a selectively turned-on functionality.
If this feature is enabled in the cluster, the users will be able to get notified of the status changes of their jobs.
The users should specify which status changes of their jobs to be notified in the job config. Here's one job config example (only extra field):
extras:
jobStatusChangeNotification:
running: true
succeeded: true
stopped: false
failed: true
retried: false
In this example, the user will be notified when this job starts running & has succeeded.
Please notice that the notification is guaranteed for succeeded, stopped, failed, retried status change.
But OpenPAI may fail to catch the running status change if the job fails very soon after starting running.
Distributed Job Examples
TensorFlow CIFAR10
This example is a TensorFlow CIFAR-10 training job, which runs a parameter server and a worker. This job needs at least 5 GPUs. Please refer to tensorflow-cifar10.yaml.
Horovod PyTorch
This example, horovod-pytorch-synthetic-benchmark.yaml, is a Horovod benchmark using PyTorch and Open MPI. Please make sure the IFNAME setting in the job yaml fits your environment. It needs at least 8 GPUs.
InfiniBand Jobs
Here's an example for an InfiniBand job:
protocolVersion: 2
name: horovod_pytorch
type: job
version: horovod0.16.4-tf1.12.0-torch1.1.0-mxnet1.4.1-py3.5
contributor: OpenPAI
description: |
This is a distributed synthetic benchmark for Horovod with the PyTorch backend running on OpenPAI.
It runs [Horovod with Open MPI](https://github.com/horovod/horovod/blob/master/docs/mpirun.rst).
parameters:
model: resnet50
batchsize: 64
# Make sure IFNAME fits the node
NCCL options for InfiniBand
nccl: >-
-x NCCL_DEBUG=INFO
-x NCCL_IB_DISABLE=0
-x NCCL_IB_GDR_LEVEL=1
-x NCCL_IB_HCA=mlx5_0:1
-x NCCL_SOCKET_IFNAME=ib0
-x HOROVOD_MPI_THREADS_DISABLE=1
prerequisites:
- protocolVersion: 2
name: horovod_official
type: dockerimage
contributor : Horovod
uri : horovod/horovod:0.16.4-tf1.12.0-torch1.1.0-mxnet1.4.1-py3.5
taskRoles:
master:
instances: 1
completion:
minSucceededInstances: 1
dockerImage: horovod_official
resourcePerInstance:
cpu: 16
memoryMB: 16384
gpu: 4
extraContainerOptions:
infiniband: true
commands:
- sleep 10
- >
mpirun --allow-run-as-root
-np 8 -H master-0:4,worker-0:4
-bind-to none -map-by slot
-mca pml ob1
-mca btl ^openib
-mca btl_tcp_if_exclude lo,docker0
<% $parameters.nccl %>
-x PATH -x LD_LIBRARY_PATH
python pytorch_synthetic_benchmark.py
--model <% $parameters.model %>
--batch-size <% $parameters.batchsize %>
worker:
instances: 1
dockerImage: horovod_official
resourcePerInstance:
cpu: 16
memoryMB: 16384
gpu: 4
commands:
- sleep infinity
extras:
com.microsoft.pai.runtimeplugin:
- plugin: ssh
parameters:
jobssh: true
sshbarrier: true
Make sure the InfiniBand driver has been installed successfully on the worker nodes, and HCA name and network interface name are set correctly.