快速开始
提交一个Hello World任务
OpenPAI的 任务 定义了一个特定环境下执行的代码和命令。它可以在单个节点上运行,也可以分布式运行。
作为快速入门,请先下载hello-world-job.yaml。
然后登录到OpenPAI的网页端,点击Submit Job -> Import Config,选择刚刚下载好的hello-world-job.yaml文件,提交任务:
现在您的第一个openPAI任务已经开始了!
查看Stdout、Stderr、所有日志和运行指标
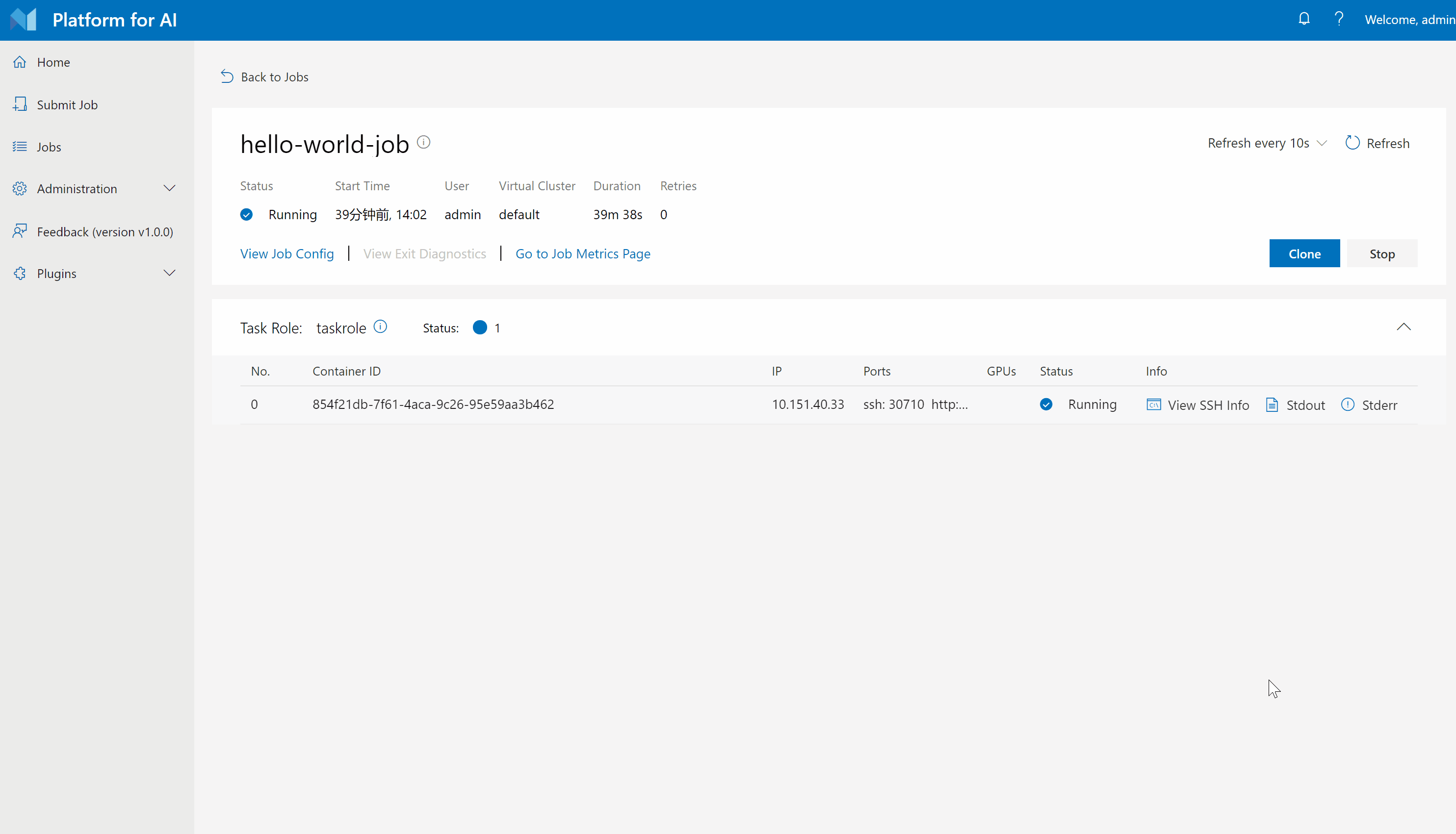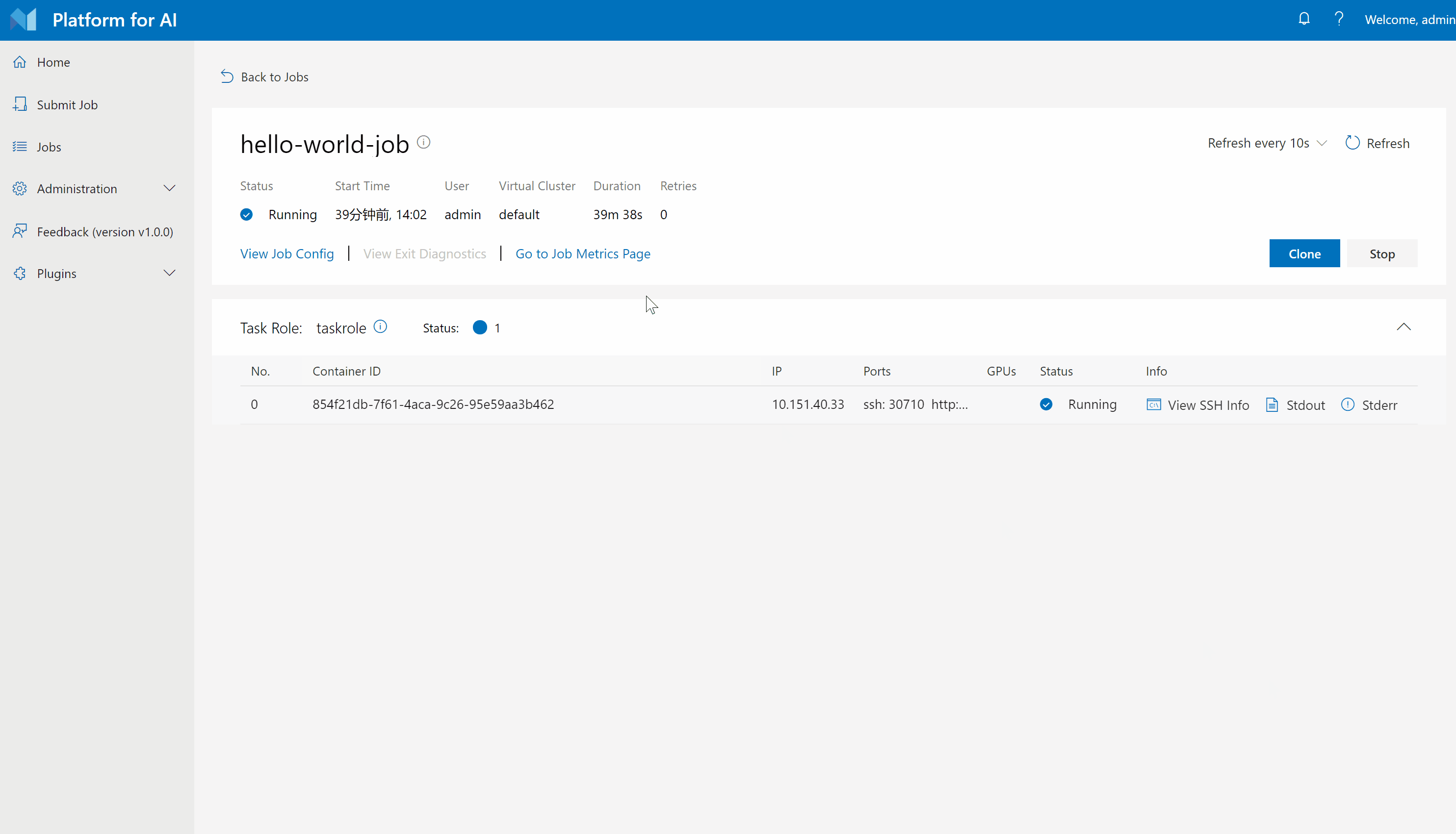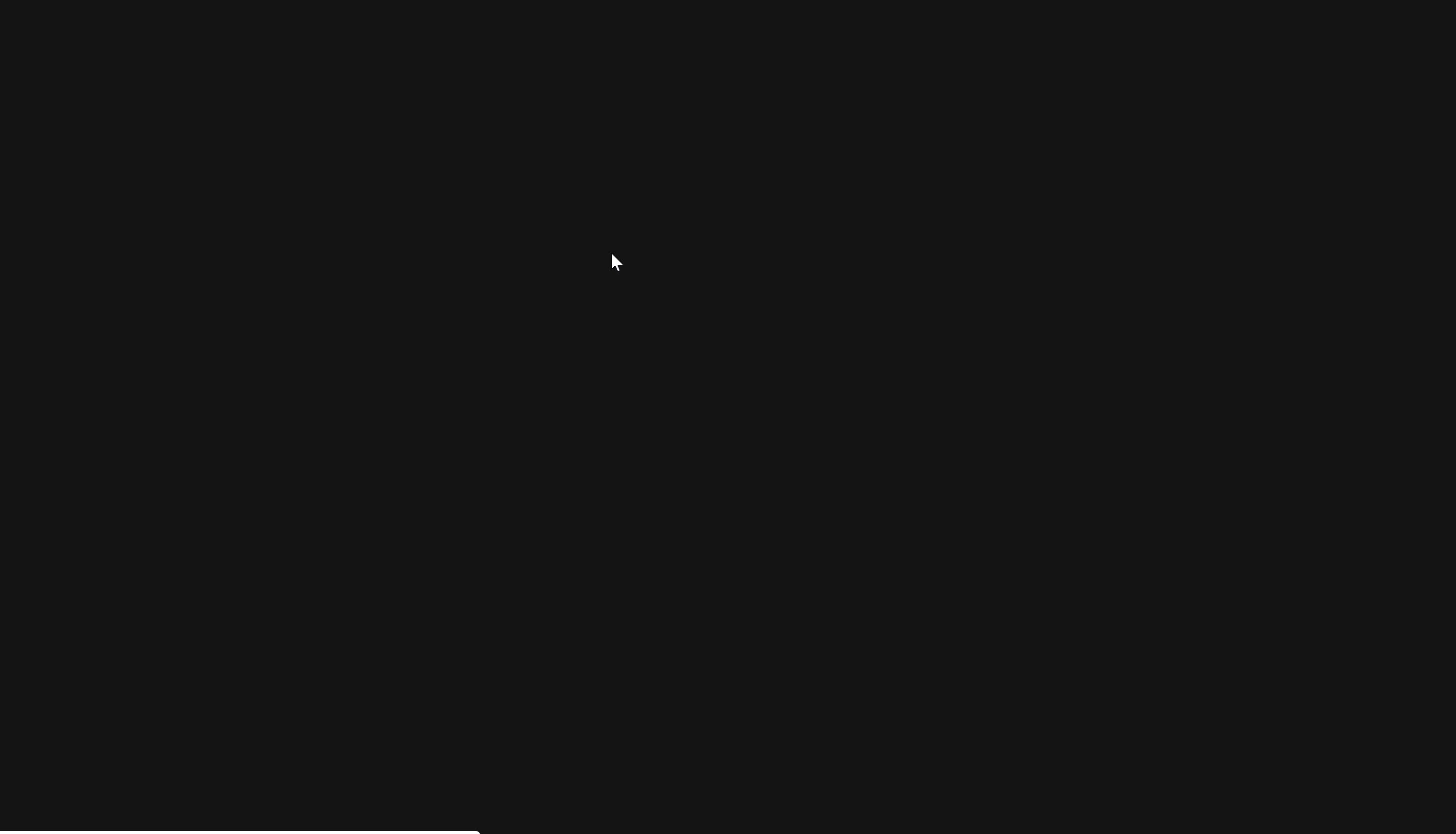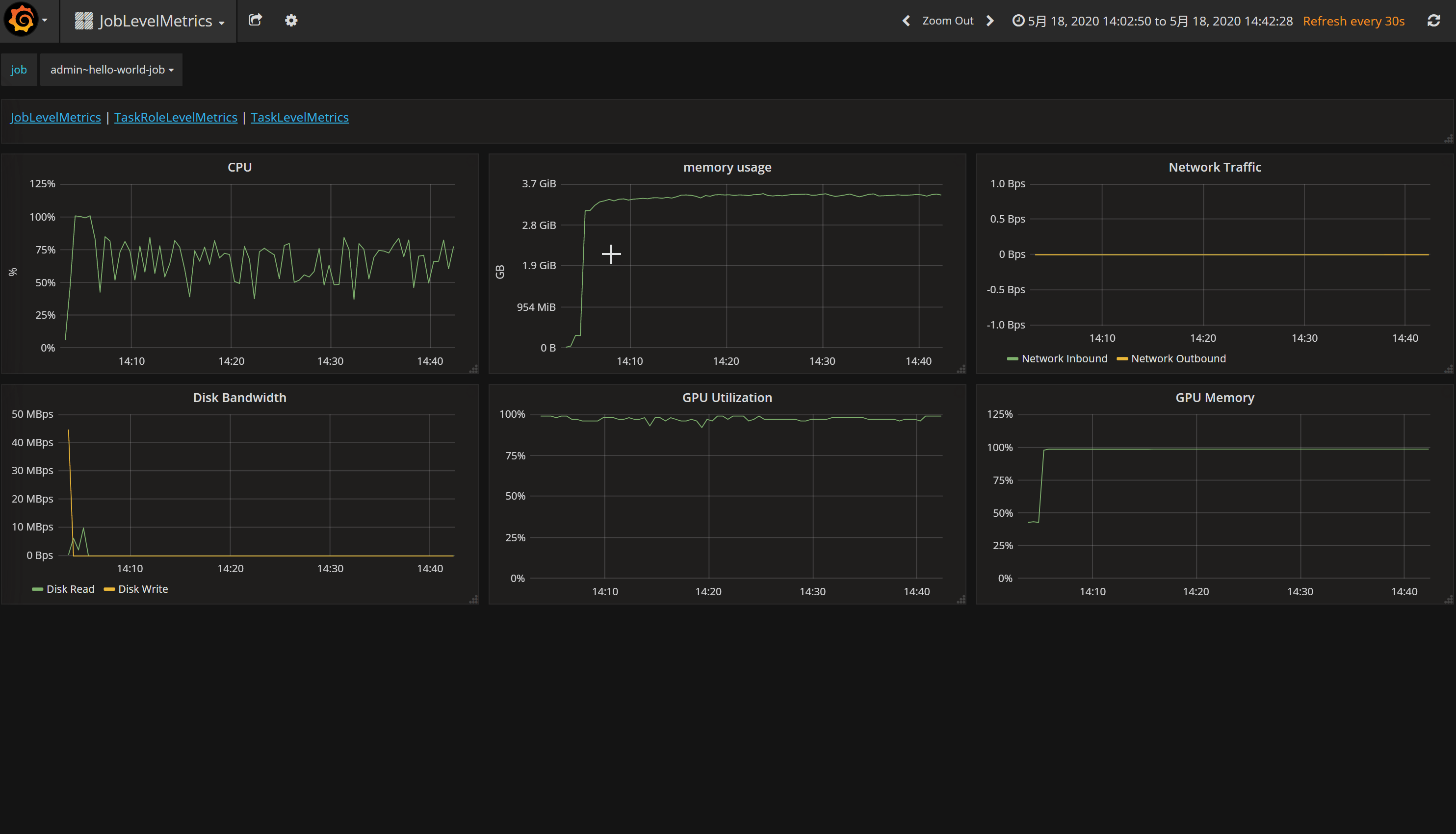
上述Hello World任务基于TensorFlow实现。这个任务在CIFAR-10数据集上训练了1000步,生成了一个简单的模型。您可以通过检查运行日志或在网页端查看指标以监控该任务。
点击 Stdout 和 Stderr 按钮,可以在任务详细信息页面上看到这个任务的标准输出和标准错误日志。如果要查看合并的日志,可以点击右侧的 ... ,选择 Stdout + Stderr。
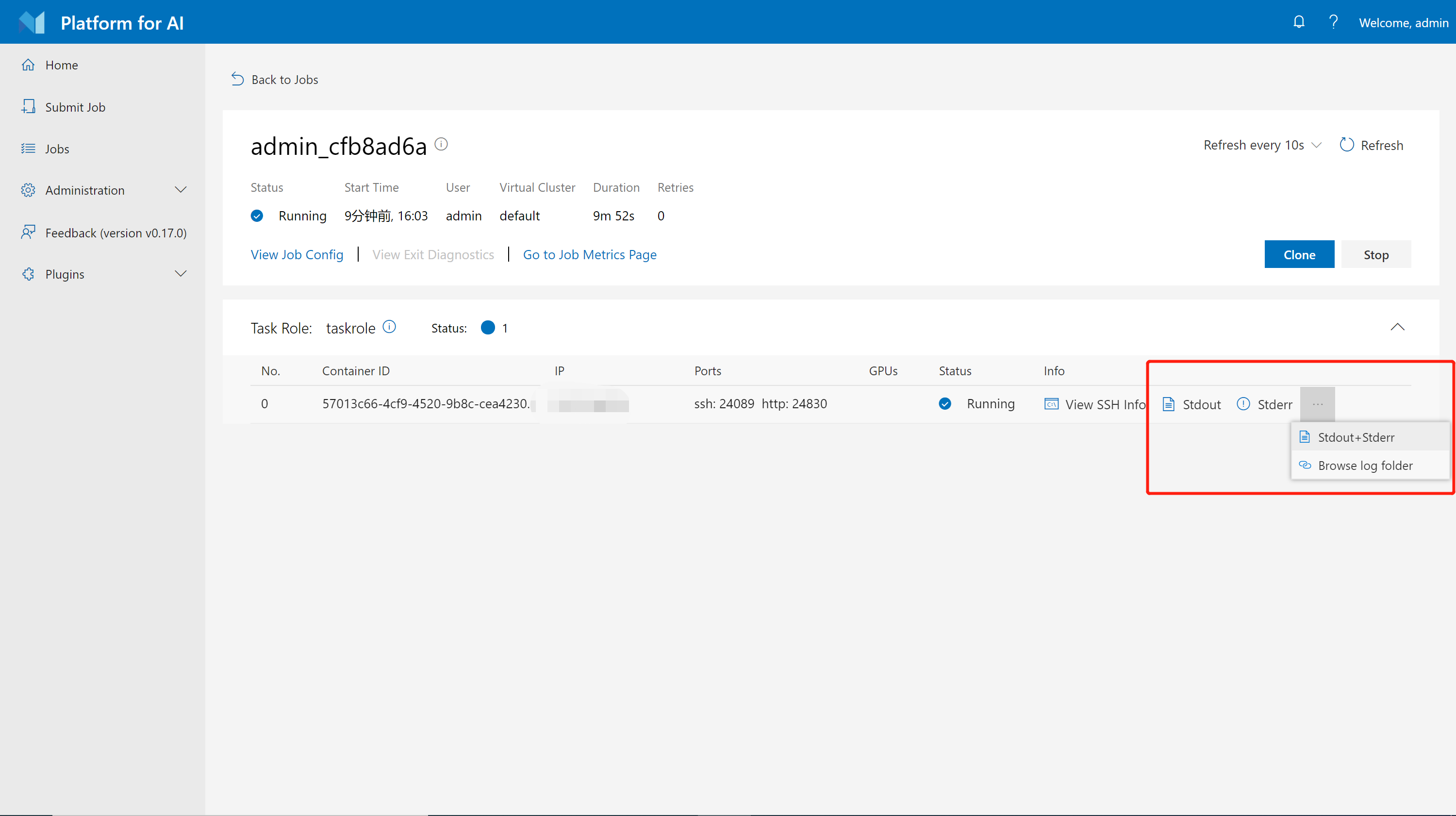
如下图所示,我们仅在对话框中显示最近16KB的日志。点击 View Full Log 以获取完整日志。
您还可以通过点击 Go to Job Metrics Page 来查看各项监控指标,这些指标(如CPU/GPU利用率、网络使用情况等)会在新窗口中显示。
逐步提交Hello World任务
除了导入任务配置文件外,您还可以直接通过网页提交Hello World任务。请参考下面的步骤:
第一步: 登录OpenPAI网页端。
第二步: 点击左侧窗格的 Submit Job,然后点击 Single Job 进入此页面。
第三步: 选择您的虚拟集群,并为任务命名。然后将以下命令复制到命令框中。
git clone https://github.com/tensorflow/models
cd models
git reset --hard 62bf6fc0bb2b41a4fb851909c132647a7e0774b0
cd research/slim
python download_and_convert_data.py --dataset_name=cifar10 --dataset_dir=/tmp/data
python train_image_classifier.py --dataset_name=cifar10 --dataset_dir=/tmp/data --max_number_of_steps=1000
注意:请 不要 在命令框中使用 # 进行注释或使用 \ 进行续行。现在使用这些符号可能会破坏语法,将来会支持使用。
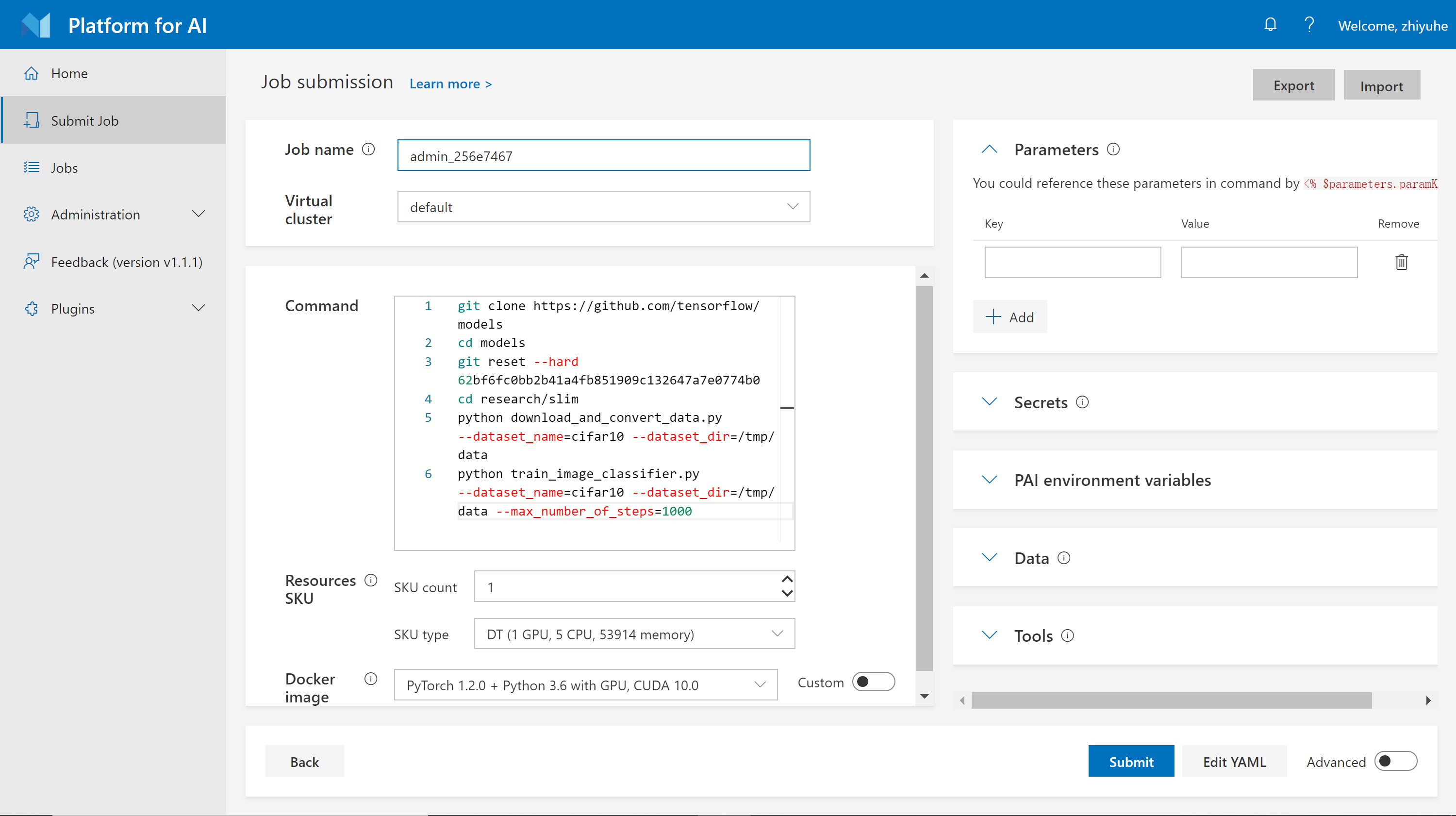
步骤四: 指定您需要的资源。在一个实例中,OpenPAI使用 resource SKU 来量化资源。例如,此处的 1 个 DT SKU 表示 1 个 GPU,5 个 CPU,和 53914MB 内存。如果您指定一个DT SKU,您将会得到一个包含 1 个 GPU,5 个 CPU 和 53914MB 内存的容器。如果您指定两个DT SKU,则会得到一个包含 2 个 GPU, 10 个 CPU 和 107828MB 内存的容器。
步骤五: 指定docker镜像。您可以使用列出的docker镜像,也可以使用自己的镜像。这里我们选择 TensorFlow 1.15.0 + Python 3.6 with GPU, CUDA 10.0,这是一个预先构建的镜像。我们将在Docker镜像和任务示例中介绍有关Docker镜像的更多信息。
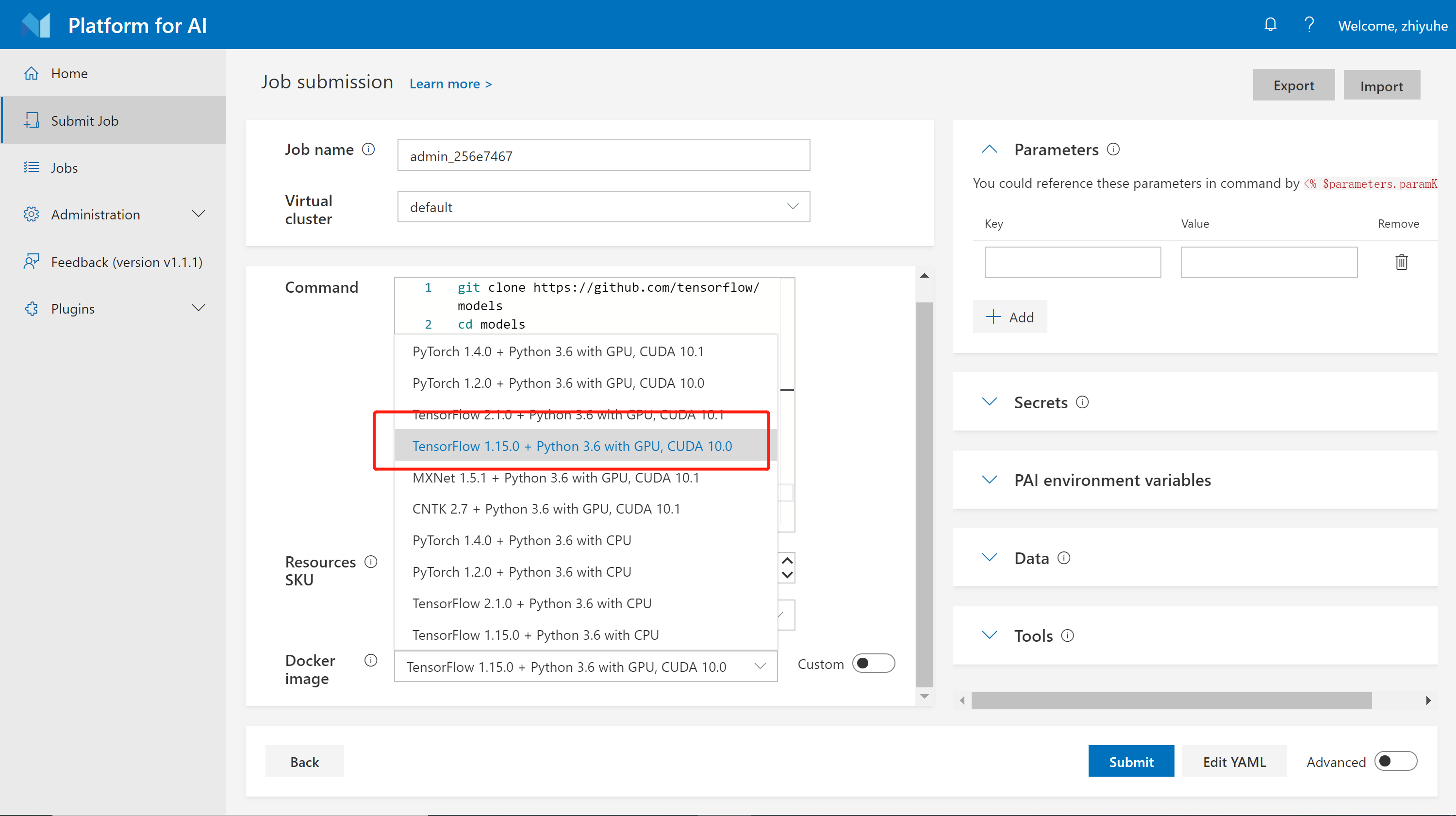
步骤六: 点击 Submit 提交任务。
学习Hello World任务
以下是提交页面上配置信息的一些详细说明:
-
Job name 是当前任务的名字。在同一个用户帐户的所有任务中,它必须是唯一的。有意义的名字有助于良好地管理任务。
-
Command 是在此任务角色中运行的命令,它可以是多行的。例如,在 Hello World 任务中,命令从Github克隆代码、下载数据,然后执行训练过程。如果一个命令失败了(退出时返回非零),接下来的命令将不继续执行。这个行为未来可能会改变。
-
GPU count, CPU vcore count, Memory (MB) 很容易理解。它们指定了相应的硬件资源,包括GPU的数量,CPU内核的数量和以MB为单位的内存量。
我们将在如何使用高级任务设置中介绍有关任务配置的更多细节。