如何使用高级任务设置
参数和秘密参数
我们通常会使用不同参数的训练不同的模型。OpenPAI支持参数定义,它提供了一种灵活的方式来训练和比较模型。您可以在 Parameters 部分定义参数,并在命令中使用 <% $parameters.paramKey %> 来引用它们。例如,下图展示了如何使用 stepNum 参数定义 Hello World 任务。
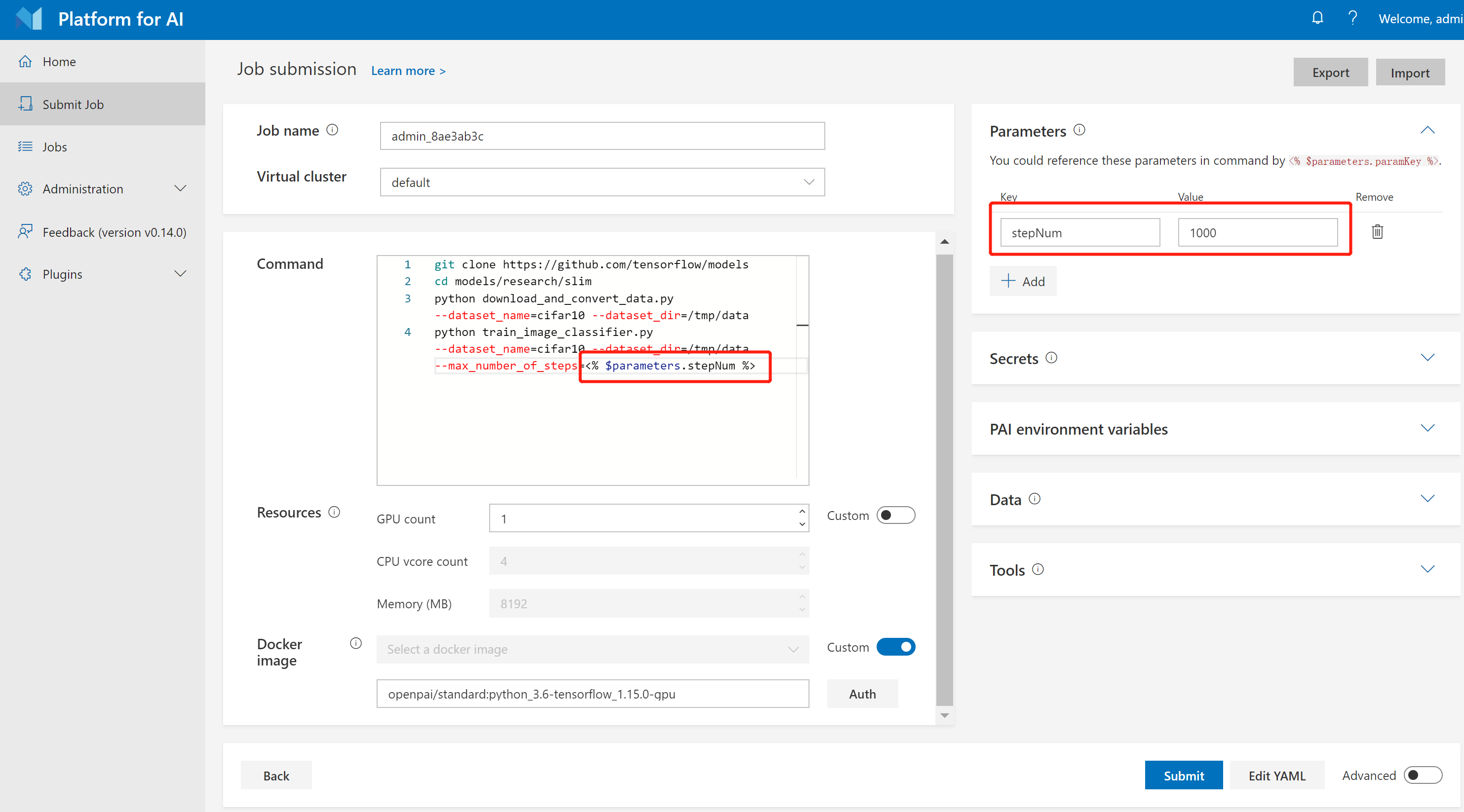
您可以定义batch size、学习率或任何您希望的内容为参数,以加快提交任务的速度。
在某些情况下,需要定义一些秘密信息,例如密码、Token等。您可以利用 Secrets 部分来定义它们。它的用法与Parameters基本相同,只是这些秘密参数不会被显示和记录。
多Task Role
如果您使用 Distributed 按钮来提交任务,则可以为任务添加不同的 task role。
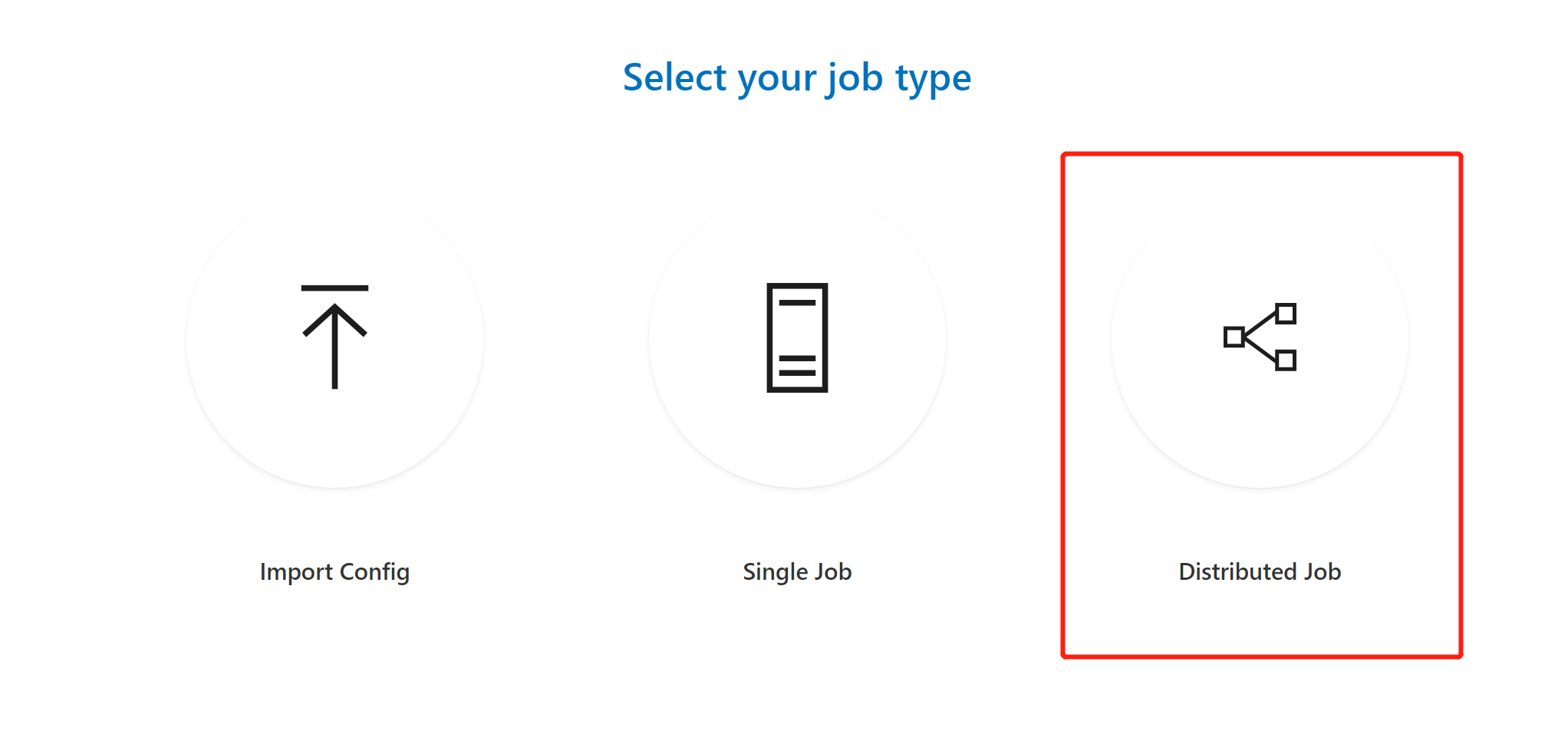
什么是 task role?单机器任务只有一个 task role,而分布式任务可能有多个 task role。例如,当TensorFlow用于运行分布式任务时,它有两个角色,包括参数服务器(parameter server)和普通worker。
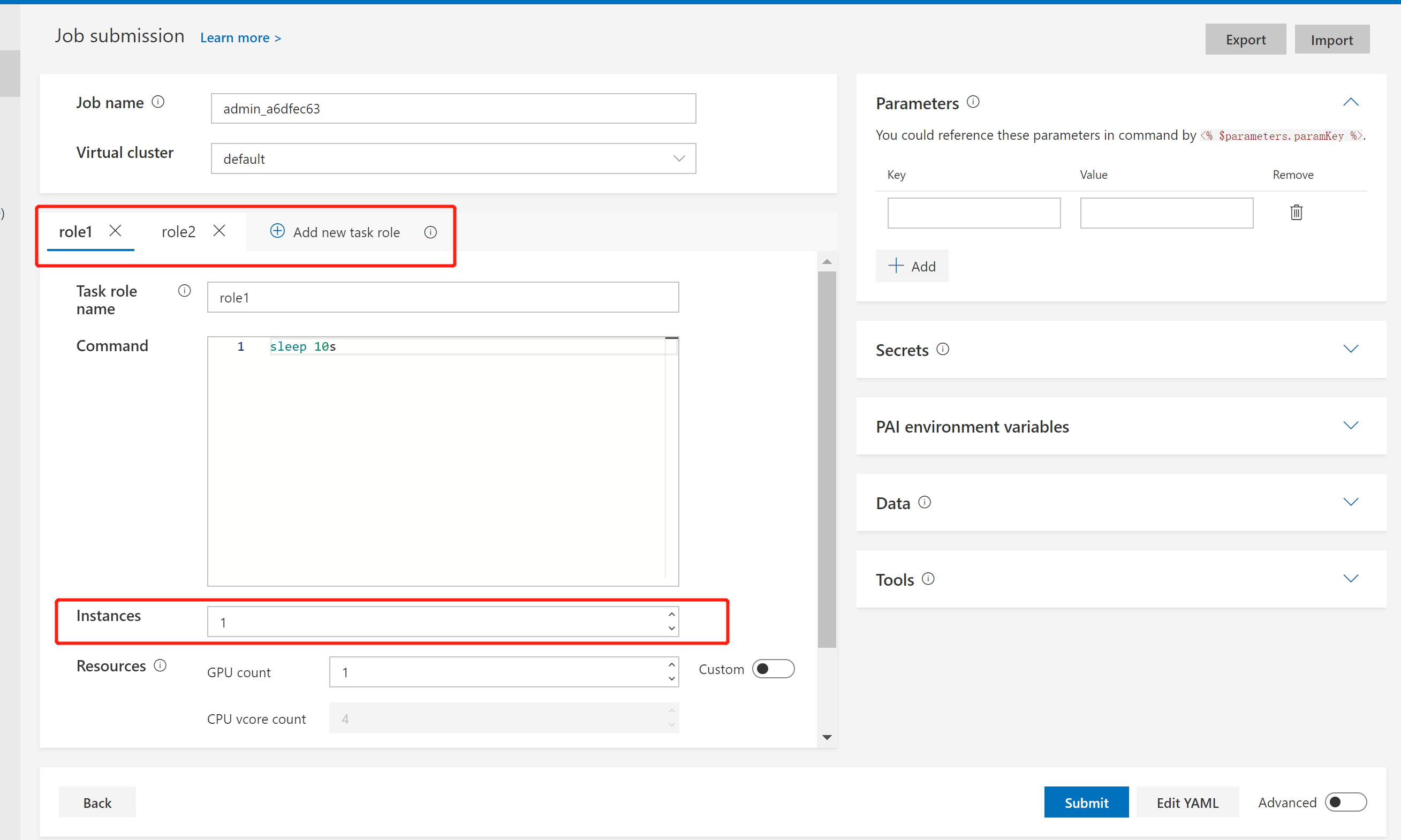
下图中的 Instances 是该 task role 的 instance 数量。例如,如果给TensorFlow的worker task role设置 Instances 为 8,就意味着这个worker task role应该有8个Docker容器。
环境变量和端口预约
在分布式任务中,一个 task 可能和其他 task 通信(这里 task 指一个 task role 里的单个instance)。因此,一个 task 需要知道其他 task 的运行时信息,例如IP、端口等。系统将这些运行时信息作为环境变量公开给每个 task 的 Docker 容器。用户可以在容器中编写代码访问运行时环境变量来相互通信。
下面是可以在Docker容器中访问的环境变量的完整列表:
| 类别 | 环境变量名 | 描述 |
|---|---|---|
| 任务级别 | PAI_JOB_NAME | 配置文件中的 jobName |
| PAI_USER_NAME | 提交任务的用户 | |
| PAI_DEFAULT_FS_URI | PAI 中的默认文件系统 uri | |
| Task role级别 | PAI_TASK_ROLE_COUNT | 配置文件中的 task role 总数 |
| PAI_TASK_ROLE_LIST | 逗号分隔配置文件中的所有 task role 名 | |
PAI_TASK_ROLE_TASK_COUNT_$taskRole |
Task role 的 task 数量 | |
PAI_HOST_IP_$taskRole_$taskIndex |
taskRole 中 taskIndex task 的主机 IP |
|
PAI_PORT_LIST_$taskRole_$taskIndex_$portType |
taskRole中 taskIndex task 的 $portType 端口列表 |
|
PAI_RESOURCE_$taskRole |
"gpuNumber,cpuNumber,memMB,shmMB" 格式的 task role 的资源需求 | |
PAI_MIN_FAILED_TASK_COUNT_$taskRole |
Task role 的 taskRole.minFailedTaskCount |
|
PAI_MIN_SUCCEEDED_TASK_COUNT_$taskRole |
Task role 的 taskRole.minSucceededTaskCount |
|
| 当前task role | PAI_CURRENT_TASK_ROLE_NAME | 当前 task role 的 taskRole.name |
| 当前task | PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX | 当前 task role 的当前 task 的索引,从0开始 |
一些环境变量与端口有关。在OpenPAI中,您可以在高级设置中为每个task保留端口,如下图所示:
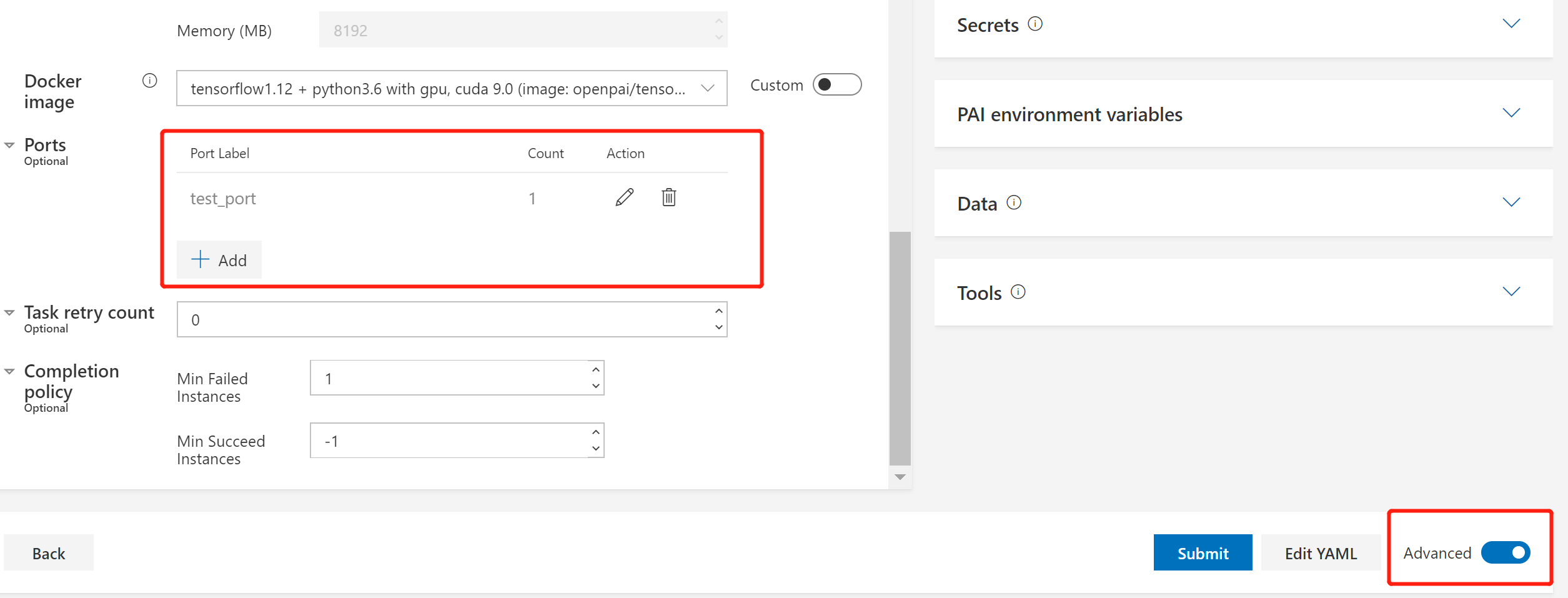
保留的端口可以在环境变量中以PAI_PORT_LIST_$taskRole_$taskIndex_$portLabel形式使用,其中 $taskIndex 表示该 task role 的 instance 索引。
在使用时,您可以用下面两种方法来引用已经声明的端口(或端口列表):
- 如下,使用
bash支持的 Indirection
MY_PORT="PAI_PORT_LIST_${PAI_CURRENT_TASK_ROLE_NAME}_${PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX}_<port-label>"
PORT=${!MY_PORT}
注意您需要使用 $PAI_CURRENT_TASK_ROLE_NAME 和 $PAI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX
- 使用一个即将弃用的 环境变量来获取当前容器中的端口(或端口列表),例如
PAI_CONTAINER_HOST_<port-label>_PORT_LIST
任务的退出诊断、重试策略和完成策略
任务中总是存在不同类型的错误。在 OpenPAI 中,错误自动被分为 3 类:
- 瞬时错误:这种错误被认为是临时的,很有可能通过重试解决。
- 永久错误:这种错误被认为是永久的,重试可能没有帮助。
- 未知错误:除了瞬时错误和永久错误之外的错误。
在任务中,发生瞬时错误将一直重试,发生永久错误则永远不会重试。如果发生未知错误,PAI 将根据用户设置来重试任务。要为任务设置重试策略和完成策略,请切换至 Advanced 模式,如下图所示:
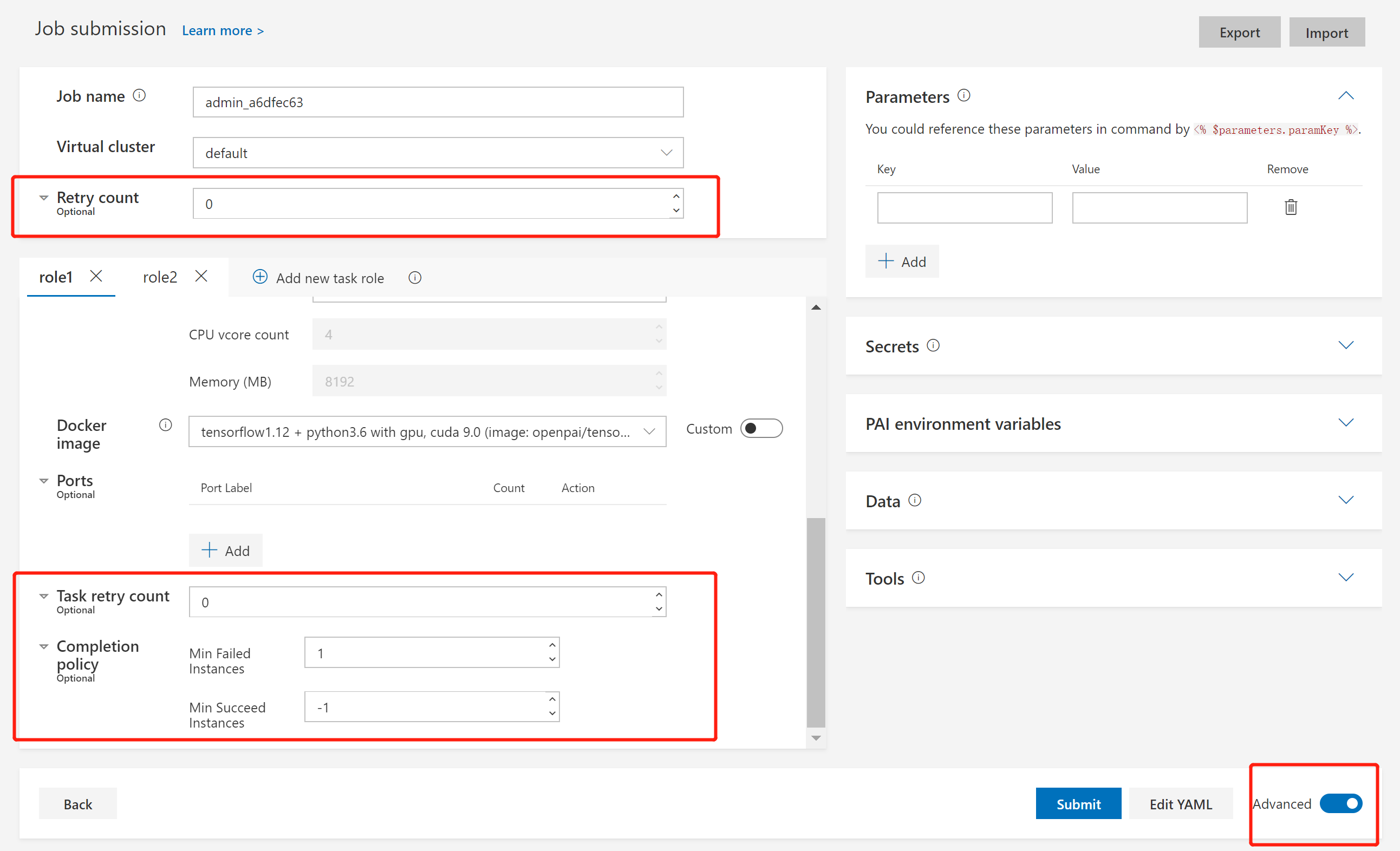
这里有三个可设置项: Retry count、Task retry count 和 Completion policy。为了更好了理解它们,您需要先认识到一个任务是由多个 task 组成的。一个 task 代表一个 task role 里的单一 instance。 Task retry count 用于 task 级别的重试。Retry count 和 Completion policy 用于任务级别的重试。
首先,让我们来看 Retry count 和 Completion policy。
在 Completion policy 中,有两个设置: Min Failed Instances 和 Min Succeed Instances。Min Failed Instances 是指会使整个任务失败的失败 task 数量。它应该为 -1 或大于等于 1。如果将它设置为 -1,不论多少 task 失败,任务都将会成功。默认值为 1,这意味着 1 个失败的 task 将会导致整个任务的失败。 Min Succeed Instances 表示会使整个任务成功的成功 task 数量。它应该是 -1 或大于等于 1。如果将其设置为 -1,则任务只会在所有 task 完成且未触发 Min Failed Instances 时成功。默认值是 -1。
如果任务满足: 1. Completion policy 之后仍没有成功 2. 失败是由于未知错误引起的 3. Retry count 是大于0的,那么将会重试整个任务。如果您需要更多次重试,将 Retry count 设置为更大的数字即可。
最后,对于 Task retry count,它是单个 task 的最大重试次数。需要特别注意的是,除非您在 任务协议 里将 extras.gangAllocation 设置为 false,否则此设置不会生效。
任务协议、导出和导入任务
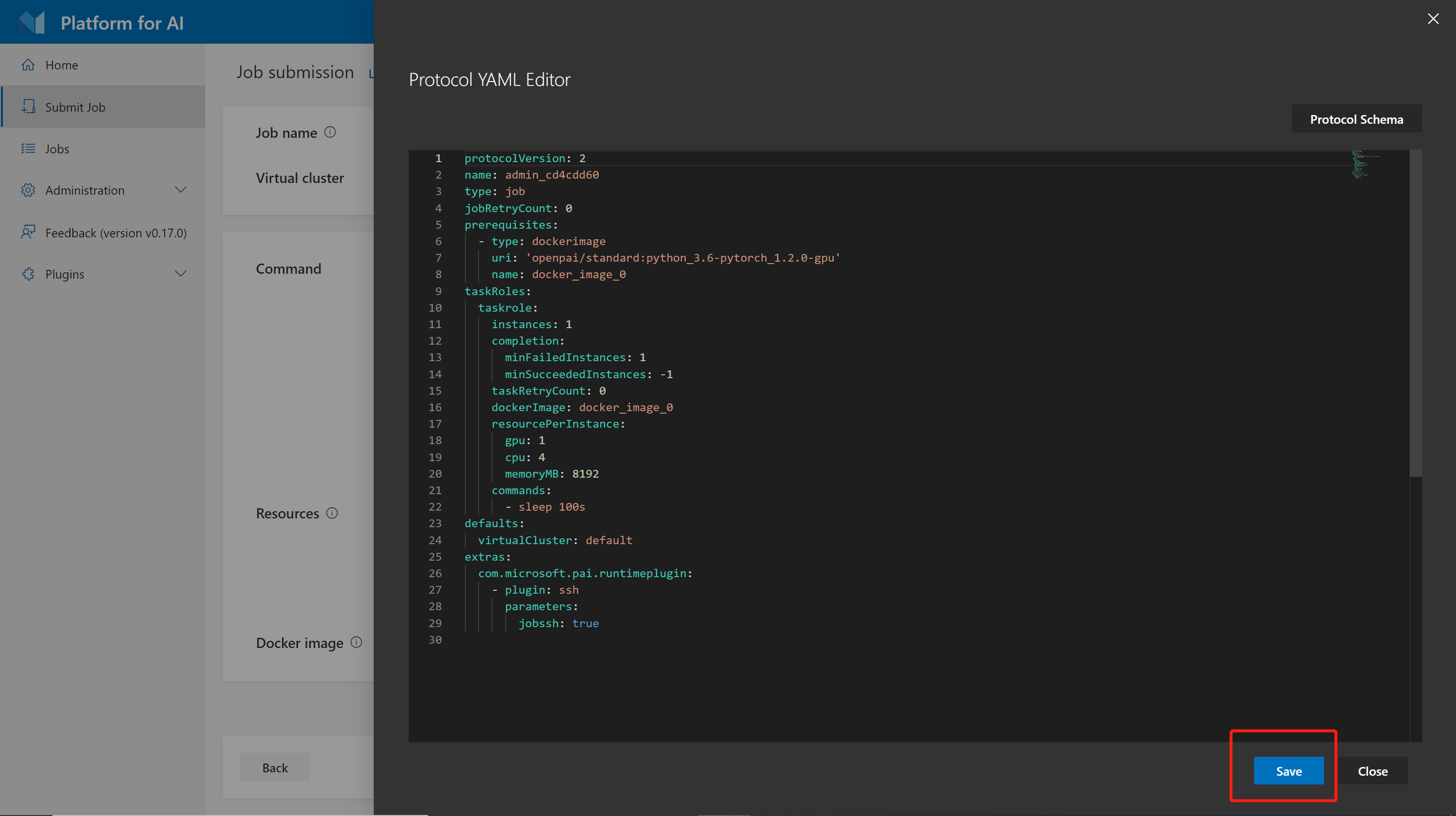
在 OpenPAI 中,所有的任务都由 YAML (一种标记语言)表示。可以点击 Edit YAML 按钮直接编辑YAML内容。
点击 Save 按钮保存所有更改:
您还可以使用 Export 和 Import 按钮导出和导入YAML文件:
任务协议的完整参考资料请查阅 任务协议。
使用 Prerequisites
OpenPAI 的任务协议 支持用户在每个task role中使用不同种类的 prerequisites (例如 dockerimage、data 和 script)。prerequisites 是在任务协议中可分享的模块。例如,一个数据集可以被定义为一个 prerequisite ,并且被不同的任务使用。
这里是一个使用 prerequisites 的例子:
protocolVersion: 2
name: test_prerequisites
type: job
jobRetryCount: 0
prerequisites:
- type: script
name: install-git
plugin: com.microsoft.pai.runtimeplugin.cmd
callbacks:
- event: taskStarts
commands:
- apt update
- apt install -y git
- type: data
name: covid-19-data
plugin: com.microsoft.pai.runtimeplugin.cmd
callbacks:
- event: taskStarts
commands:
- mkdir -p /dataset/covid-19
- >-
git clone https://github.com/ieee8023/covid-chestxray-dataset.git
/dataset/covid-19
- type: dockerimage
uri: 'ubuntu:18.04'
name: docker_image_0
taskRoles:
taskrole:
instances: 1
completion:
minFailedInstances: 1
taskRetryCount: 0
prerequisites:
- install-git
- covid-19-data
dockerImage: docker_image_0
resourcePerInstance:
gpu: 1
cpu: 3
memoryMB: 29065
commands:
- ls -la /dataset/covid-19
defaults:
virtualCluster: default
extras:
com.microsoft.pai.runtimeplugin:
- plugin: ssh
parameters:
jobssh: true
在最高层的 prerequisites 域中,我们定义了两个 prerequisites:一个是 install-git,另外一个是 covid-19-data。covid-19-data 将一个数据集下载到文件夹 /dataset/covid-19 。而install-git 是一个安装 git 的 prerequisites。
在 taskRoles.taskrole.prerequisites 域中,我们使用下面的顺序引用了这两个 prerequisites:1. install-git 2. covid-19-data。因此,install-git 将会先于 covid-19 执行。在这两个 prerequisites 被成功执行后,用户就可以使用 /dataset/covid-19 中的数据了。
完整的 prerequisites 定义如下:
prerequisites:
- name: string # required, unique name to find the prerequisite (from local or marketplace)
type: "dockerimage | script | data | output" # for survey purpose (except dockerimage), useless for backend
plugin: string # optional, the executor to handle current prerequisite; only support com.microsoft.pai.runtimeplugin.cmd for now
require: [] # optional, other prerequisites on which the current one depends; will be parsed by backend automatically
failurePolicy: "ignore | fail" # optional, same default as runtime plugin
uri: string | array # optional, for backward compatibility
# plugin-specific properties
# Other parameters for the plugin can be inserted here.
# For example, "callbacks" is a parameter for com.microsoft.pai.runtimeplugin.cmd.
taskRoles:
taskrole:
prerequisites: # specified prerequisites will be used in the task role.
- prerequisite-1 # on taskStarts, will execute in order
- prerequisite-2 # on taskSucceeds, will execute in reverse order
在未来,OpenPAI 会提供更方便的方法来让集群用户管理和分享不同种类的 prerequisites。
分布式任务示例
TensorFlow CIFAR10
此示例是 Tensorflow CIFAR-10 训练任务,它运行了一个参数服务器(parameter server)和一个worker。这项任务需要至少 5 个 GPU。请参考 tensorflow-cifar10.yaml。
Horovod PyTorch
示例horovod-pytorch-synthetic-benchmark.yaml是一个使用了PyTorch 和 Open MPI 的 Horovod benchmark。请确保任务 yaml 中的 IFNAME 设置适合您的环境。它至少需要 8 个 GPU。
InfiniBand 任务
这是 InfiniBand 任务的示例:
protocolVersion: 2
name: horovod_pytorch
type: job
version: horovod0.16.4-tf1.12.0-torch1.1.0-mxnet1.4.1-py3.5
contributor: OpenPAI
description: |
This is a distributed synthetic benchmark for Horovod with PyTorch backend running on OpenPAI.
It runs [Horovod with Open MPI](https://github.com/horovod/horovod/blob/master/docs/mpirun.rst).
parameters:
model: resnet50
batchsize: 64
# Make sure IFNAME fits the node
NCCL options for InfiniBand
nccl: >-
-x NCCL_DEBUG=INFO
-x NCCL_IB_DISABLE=0
-x NCCL_IB_GDR_LEVEL=1
-x NCCL_IB_HCA=mlx5_0:1
-x NCCL_SOCKET_IFNAME=ib0
-x HOROVOD_MPI_THREADS_DISABLE=1
prerequisites:
- protocolVersion: 2
name: horovod_official
type: dockerimage
contributor : Horovod
uri : horovod/horovod:0.16.4-tf1.12.0-torch1.1.0-mxnet1.4.1-py3.5
taskRoles:
master:
instances: 1
completion:
minSucceededInstances: 1
dockerImage: horovod_official
resourcePerInstance:
cpu: 16
memoryMB: 16384
gpu: 4
extraContainerOptions:
infiniband: true
commands:
- sleep 10
- >
mpirun --allow-run-as-root
-np 8 -H master-0:4,worker-0:4
-bind-to none -map-by slot
-mca pml ob1
-mca btl ^openib
-mca btl_tcp_if_exclude lo,docker0
<% $parameters.nccl %>
-x PATH -x LD_LIBRARY_PATH
python pytorch_synthetic_benchmark.py
--model <% $parameters.model %>
--batch-size <% $parameters.batchsize %>
worker:
instances: 1
dockerImage: horovod_official
resourcePerInstance:
cpu: 16
memoryMB: 16384
gpu: 4
commands:
- sleep infinity
extras:
com.microsoft.pai.runtimeplugin:
- plugin: ssh
parameters:
jobssh: true
sshbarrier: true
请确保已经在 worker 节点上安装了 InfiniBand 驱动程序,并且HCA名称和网络接口名称已正确设置。