如何设置虚拟集群
Hived Scheduler介绍
OpenPAI 支持两种调度器:Kubernetes default scheduler 和 hivedscheduler。Hivedscheduler是一个用于深度学习的 Kubernetes Scheduler。它支持虚拟集群划分,拓扑感知的资源保证、以及性能优化的 Gang Scheduling,这些都是 k8s default scheduler 不支持的。如果您没有在安装时显式声明 enable_hived_scheduler: false,那么 Hivedscheduler 就是开启的。请注意,目前只有Hivedscheduler支持虚拟集群设置,k8s default scheduler 不支持。
设置虚拟集群 (Virtual Cluster)
GPU虚拟集群的配置
在开始之前,请阅读 此文档,以了解如何写 hived scheduler 配置。
在 services-configuration.yaml 中,有一个 hived scheduler 部分,如下:
# services-configuration.yaml
...
hivedscheduler:
config: |
physicalCluster:
skuTypes:
DT:
gpu: 1
cpu: 5
memory: 56334Mi
cellTypes:
DT-NODE:
childCellType: DT
childCellNumber: 4
isNodeLevel: true
DT-NODE-POOL:
childCellType: DT-NODE
childCellNumber: 3
physicalCells:
- cellType: DT-NODE-POOL
cellChildren:
- cellAddress: worker1
- cellAddress: worker2
- cellAddress: worker3
virtualClusters:
default:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 3
...
如果您按照 安装指南 操作,您会在 services-configuration.yaml 里找到类似的设置hived scheduler 文档包含这些字段的详细说明。您可以更新配置并建立虚拟集群。例如,在上面的设置中,我们有 3 个节点:worker1,worker2 和 worker3。它们都在 default 虚拟集群中。如果我们要创建两个 VC(Virtual Cluster,即虚拟集群),一个叫 default,包含两个节点,另一个叫 new ,包含一个节点,我们可以先修改 services-configuration.yaml:
# services-configuration.yaml
...
hivedscheduler:
config: |
physicalCluster:
skuTypes:
DT:
gpu: 1
cpu: 5
memory: 56334Mi
cellTypes:
DT-NODE:
childCellType: DT
childCellNumber: 4
isNodeLevel: true
DT-NODE-POOL:
childCellType: DT-NODE
childCellNumber: 3
physicalCells:
- cellType: DT-NODE-POOL
cellChildren:
- cellAddress: worker1
- cellAddress: worker2
- cellAddress: worker3
virtualClusters:
default:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 2
new:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 1
...
CPU虚拟集群的配置
如果您想添加CPU机器,在修改配置这一步,我们建议您设置一个纯 CPU 的虚拟集群,不要在一个虚拟集群中混合 CPU 节点和 GPU 节点。设置CPU结点时,请省略 skuTypes 中的 gpu 字段,或使用 gpu: 0。示例如下:
hivedscheduler:
config: |
physicalCluster:
skuTypes:
DT:
gpu: 1
cpu: 5
memory: 56334Mi
CPU:
cpu: 1
memory: 10240Mi
cellTypes:
DT-NODE:
childCellType: DT
childCellNumber: 4
isNodeLevel: true
DT-NODE-POOL:
childCellType: DT-NODE
childCellNumber: 3
CPU-NODE:
childCellType: CPU
childCellNumber: 8
isNodeLevel: true
CPU-NODE-POOL:
childCellType: CPU-NODE
childCellNumber: 1
physicalCells:
- cellType: DT-NODE-POOL
cellChildren:
- cellAddress: worker1
- cellAddress: worker2
- cellAddress: worker3
- cellType: CPU-NODE-POOL
cellChildren:
- cellAddress: cpu-worker1
virtualClusters:
default:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 3
cpu:
virtualCells:
- cellType: CPU-NODE-POOL.CPU-NODE
cellNumber: 1
上面示例的解释:假设我们在 Kubernetes 中有一个名为 cpu-worker1 的节点。它有 80GB 的内存和 8 个可分配的 CPU(请使用 kubectl describe node cpu-worker1 来确认可分配的资源)。然后,在skuTypes中,我们可以设置一个 CPU sku,它有 1 个 CPU 和 10240 MiB(80GiB / 8)的内存。如果需要,可以保留一些内存或 CPU。在 cellTypes 相应的设置了 CPU-NODE 和 CPU-NODE-POOL。最后,该设置将产生一个 default VC 和一个 cpu VC。cpu VC 包含一个 CPU 节点。
应用配置到集群
修改配置后,使用以下命令来应用配置:
./paictl.py service stop -n rest-server hivedscheduler
./paictl.py config push -p <config-folder> -m service
./paictl.py service start -n hivedscheduler rest-server
现在,您可以使用 OpenPAI 中的任何管理员账户测试这些新的 VC。下一节 将介绍如何向非管理员账户授予 VC 访问权限。
将集群授权给用户
管理员用户有权访问所有 VC。因此,如果您设置了一个新的 VC,可以用管理员账户来测试这个新VC。对于非管理员用户,管理员应该手动向其授予 VC 访问权限。具体方法取决于集群的 认证模式。
在基础认证模式中
在基础认证模式中,管理员可以在 User Management 页面上授予用户访问 VC 的权限。首先,点击页面的 Edit。然后,为每个用户配置 VC 访问权限,如下所示。
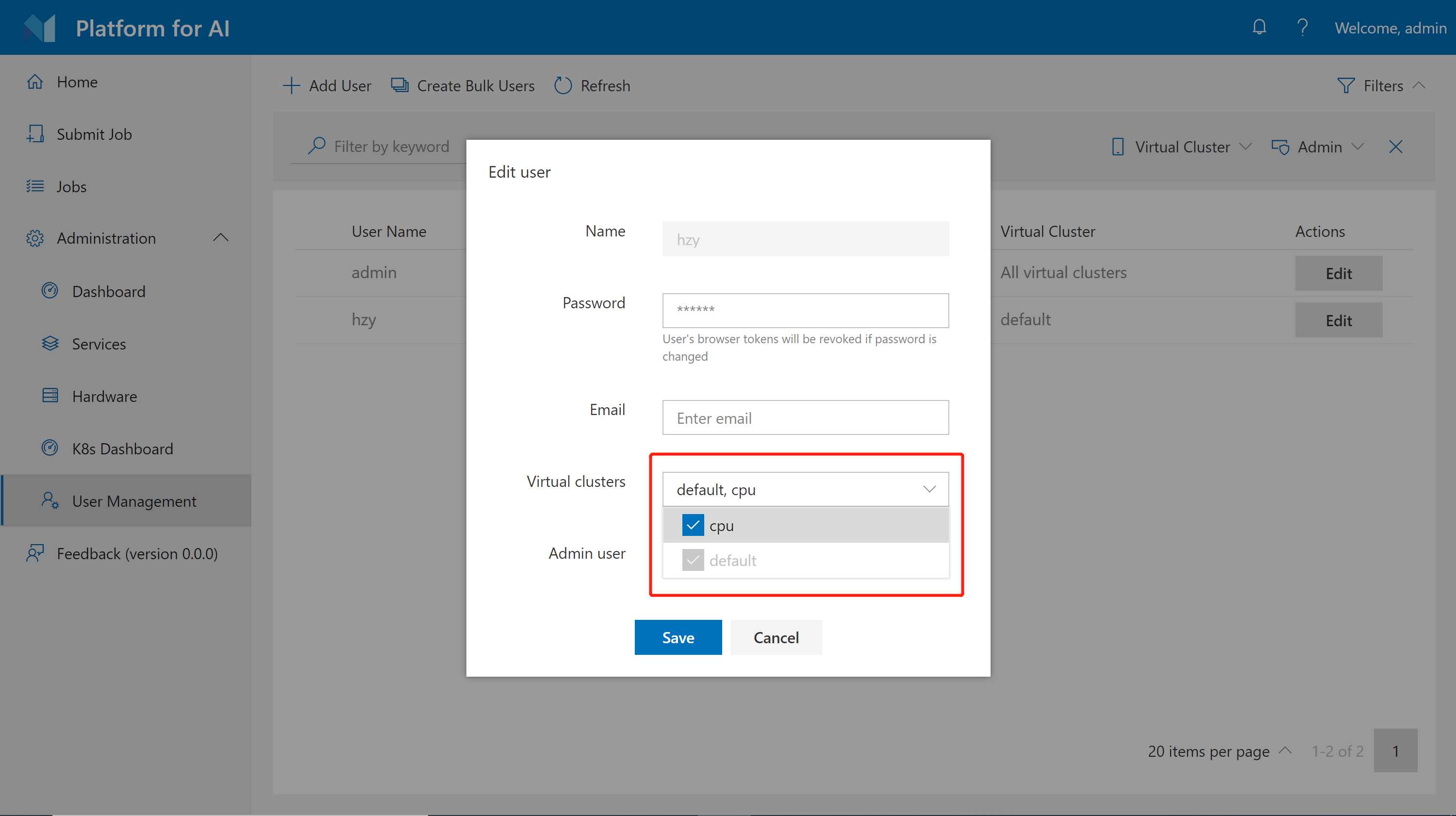
请注意您无法撤销用户对default VC的访问权限。
在AAD认证模式中
在 AAD 模式下,用户通过 AAD 服务分组。应该为每个组分配 VC 访问权限。
首先,在 services-configuration.yaml 中找到以下部分:
# services-configuration.yaml
...
group-manager:
...
grouplist:
- groupname: group1
externalName: sg1
extension:
acls:
admin: false
virtualClusters: ["vc1"]
storageConfigs: ["azure-file-storage"]
- groupname: group2
externalName: sg2
extension:
acls:
admin: false
virtualClusters: ["vc1", "vc2"]
storageConfigs: ["nfs-storage"]
...
virtualClusters 字段用于管理不同组的 VC 访问。使用以下命令应用配置更改:
./paictl.py service stop -n rest-server
./paictl.py config push -p <config-folder> -m service
./paictl.py service start -n rest-server
Worker结点含有不同硬件配置
我们建议一台 VC 应该拥有相同的硬件,表现在 hived scheduler 设置中,一个 VC 应该只包含一个 skuType。如果您有不同类型的 worker 结点(例如,不同结点上的 GPU 类型不同),请在不同的 VC 中进行配置。以下是 2 种结点的示例:
hivedscheduler:
config: |
physicalCluster:
skuTypes:
K80:
gpu: 1
cpu: 5
memory: 56334Mi
V100:
gpu: 1
cpu: 8
memory: 80000Mi
cellTypes:
K80-NODE:
childCellType: K80
childCellNumber: 4
isNodeLevel: true
K80-NODE-POOL:
childCellType: K80-NODE
childCellNumber: 2
V100-NODE:
childCellType: V100
childCellNumber: 4
isNodeLevel: true
V100-NODE-POOL:
childCellType: V100-NODE
childCellNumber: 3
physicalCells:
- cellType: K80-NODE-POOL
cellChildren:
- cellAddress: k80-worker1
- cellAddress: k80-worker2
- cellType: V100-NODE-POOL
cellChildren:
- cellAddress: v100-worker1
- cellAddress: v100-worker2
- cellAddress: v100-worker3
virtualClusters:
default:
virtualCells:
- cellType: K80-NODE-POOL.K80-NODE
cellNumber: 2
V100:
virtualCells:
- cellType: V100-NODE-POOL.V100-NODE
cellNumber: 3
在上面的示例中,我们设置了 2 个 VC:default 和 v100。default VC 有两个 K80 结点,V100 VC 有 3 个 V100 结点。每个 K80 结点有 4 个 K80 GPU,每个 V100 结点有 4 个 V100 GPU。
在同一个结点上同时设置CPU和GPU sku
如果你想要在同一个结点上同时设置CPU和GPU sku,您可以参考下面的配置,在不同的cellTypes里使用相同的cellAddress:
hivedscheduler:
config: |
physicalCluster:
skuTypes:
GPU:
gpu: 1
cpu: 4
memory: 40960Mi
CPU:
gpu: 0
cpu: 1
memory: 10240Mi
cellTypes:
GPU-NODE:
childCellType: GPU
childCellNumber: 4
isNodeLevel: true
GPU-NODE-POOL:
childCellType: GPU-NODE
childCellNumber: 2
CPU-NODE:
childCellType: CPU
childCellNumber: 12
isNodeLevel: true
CPU-NODE-POOL:
childCellType: CPU-NODE
childCellNumber: 2
physicalCells:
- cellType: GPU-NODE-POOL
cellChildren:
- cellAddress: node1
- cellAddress: node2
- cellType: CPU-NODE-POOL
cellChildren:
- cellAddress: node1
- cellAddress: node2
virtualClusters:
default:
virtualCells:
- cellType: GPU-NODE-POOL.GPU-NODE
cellNumber: 2
cpu:
virtualCells:
- cellType: CPU-NODE-POOL.CPU-NODE
cellNumber: 2
目前,在同一个结点上,我们只支持CPU和NVIDIA GPU的混合,或者CPU和AMD GPU的混合。暂不支持在同一个结点上同时存在NVIDIA和AMD GPU的情形。
使用Pinned Cell在虚拟集群中保留特定结点
在某些情况下,您可能希望保留虚拟集群中的特定节点,将作业明确提交到该结点以进行调试或快速测试。OpenPAI 提供了一种“固定”结点到虚拟集群的方法。
例如,假设您有三个 worker 结点: worker1、worker2 和 worker3,以及 2 个虚拟集群:default 和 new。default VC 有 2 个 worker,new VC 只有 1 个 worker。以下是配置示例:
# services-configuration.yaml
...
hivedscheduler:
config: |
physicalCluster:
skuTypes:
DT:
gpu: 1
cpu: 5
memory: 56334Mi
cellTypes:
DT-NODE:
childCellType: DT
childCellNumber: 4
isNodeLevel: true
DT-NODE-POOL:
childCellType: DT-NODE
childCellNumber: 3
physicalCells:
- cellType: DT-NODE-POOL
cellChildren:
- cellAddress: worker1
- cellAddress: worker2
- cellAddress: worker3
virtualClusters:
default:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 2
new:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 1
...
现在,如果要将节点 worker2 “固定”到默认的 VC。可以将配置更改为:
# services-configuration.yaml
...
hivedscheduler:
config: |
physicalCluster:
skuTypes:
DT:
gpu: 1
cpu: 5
memory: 56334Mi
cellTypes:
DT-NODE:
childCellType: DT
childCellNumber: 4
isNodeLevel: true
DT-NODE-POOL:
childCellType: DT-NODE
childCellNumber: 3
physicalCells:
- cellType: DT-NODE-POOL
cellChildren:
- cellAddress: worker1
- cellAddress: worker2
pinnedCellId: node-worker2
- cellAddress: worker3
virtualClusters:
default:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 1
pinnedCells:
- pinnedCellId: node-worker2
new:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 1
...
如您在配置中看到的,一个虚拟集群可以同时包含 virtual cells 和 pinned cells。现在 default VC 有一个 virtual cell 和一个 pinned cell。要将一个 pinned cell 包含到虚拟集群中,您应该为其指定一个 pinnedCellId。 例如上述配置将在 default VC 中保留 worker2。
在任务提交时,您可以通过在 extras.hivedScheduler.taskRoles.<task-role-name>.pinnedCellId 中指定相应的 pinned cell id,将任务显式提交到 worker2,示例如下:
protocolVersion: 2
name: job-with-pinned-cell
type: job
jobRetryCount: 0
prerequisites:
- type: dockerimage
uri: 'openpai/standard:python_3.6-pytorch_1.2.0-gpu'
name: docker_image_0
taskRoles:
myworker:
instances: 1
completion:
minFailedInstances: 1
taskRetryCount: 0
dockerImage: docker_image_0
resourcePerInstance:
gpu: 1
cpu: 4
memoryMB: 8192
commands:
- sleep 100s
defaults:
virtualCluster: default
extras:
com.microsoft.pai.runtimeplugin:
- plugin: ssh
parameters:
jobssh: true
hivedScheduler:
taskRoles:
myworker:
pinnedCellId: node-worker2