Quick Start
Submit a Hello World Job
The job of OpenPAI defines how to execute code(s) and command(s) in specified environment(s). It can be run on a single node or distributedly.
For a quick start, please download hello-world-job.yaml.
Then login to OpenPAI webportal, click Submit Job -> Import Config, select the downloaded hello-world-job.yaml file, and submit the job:
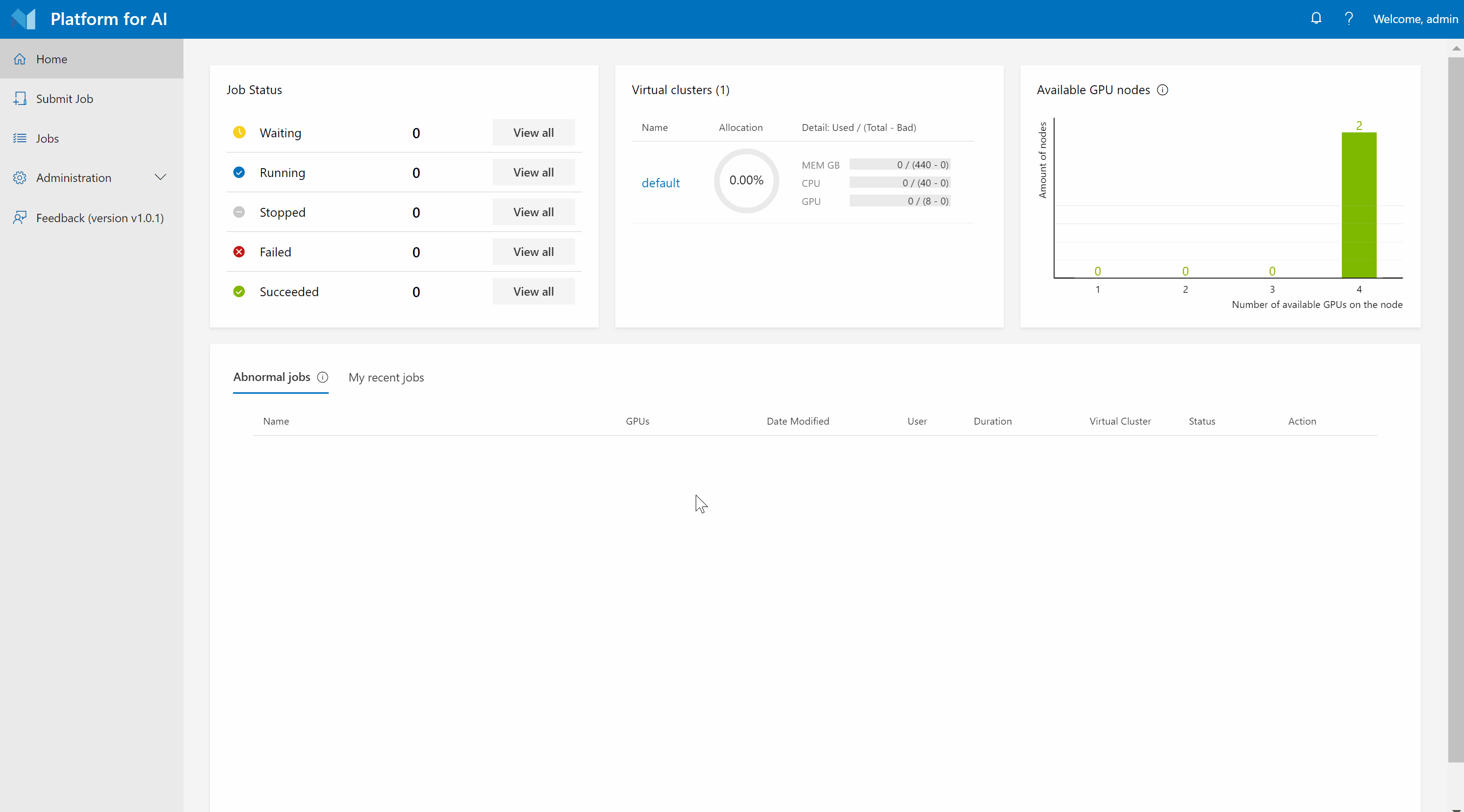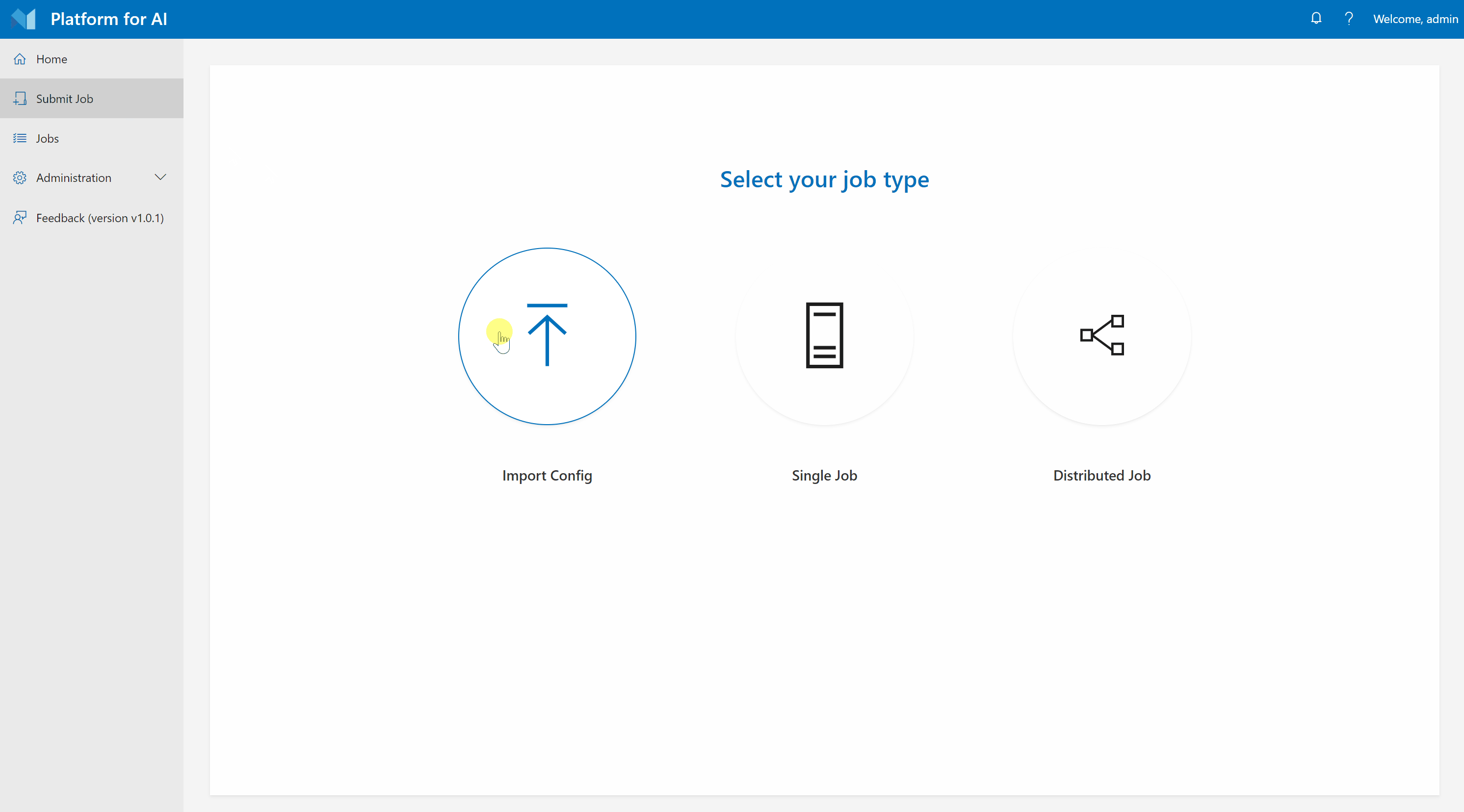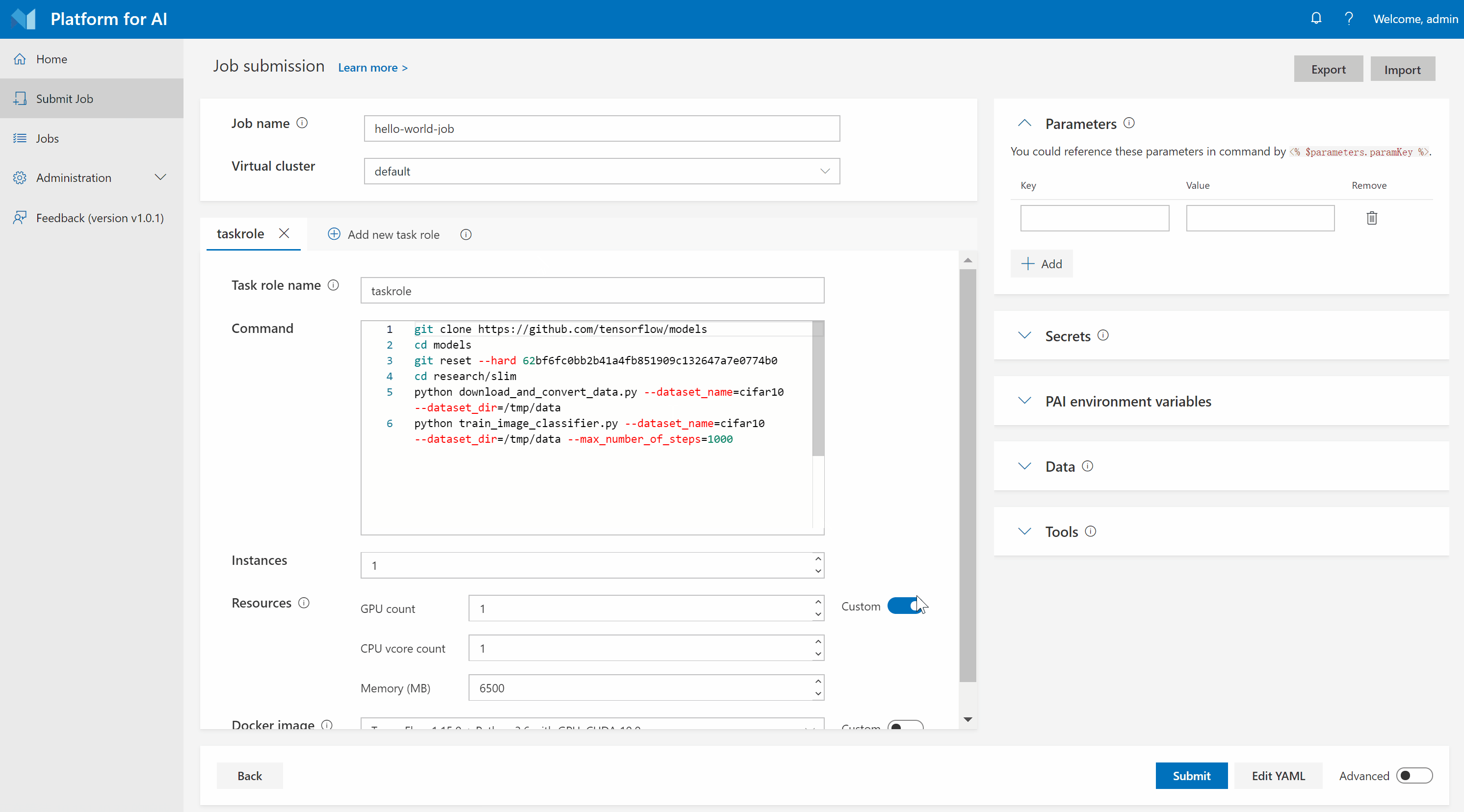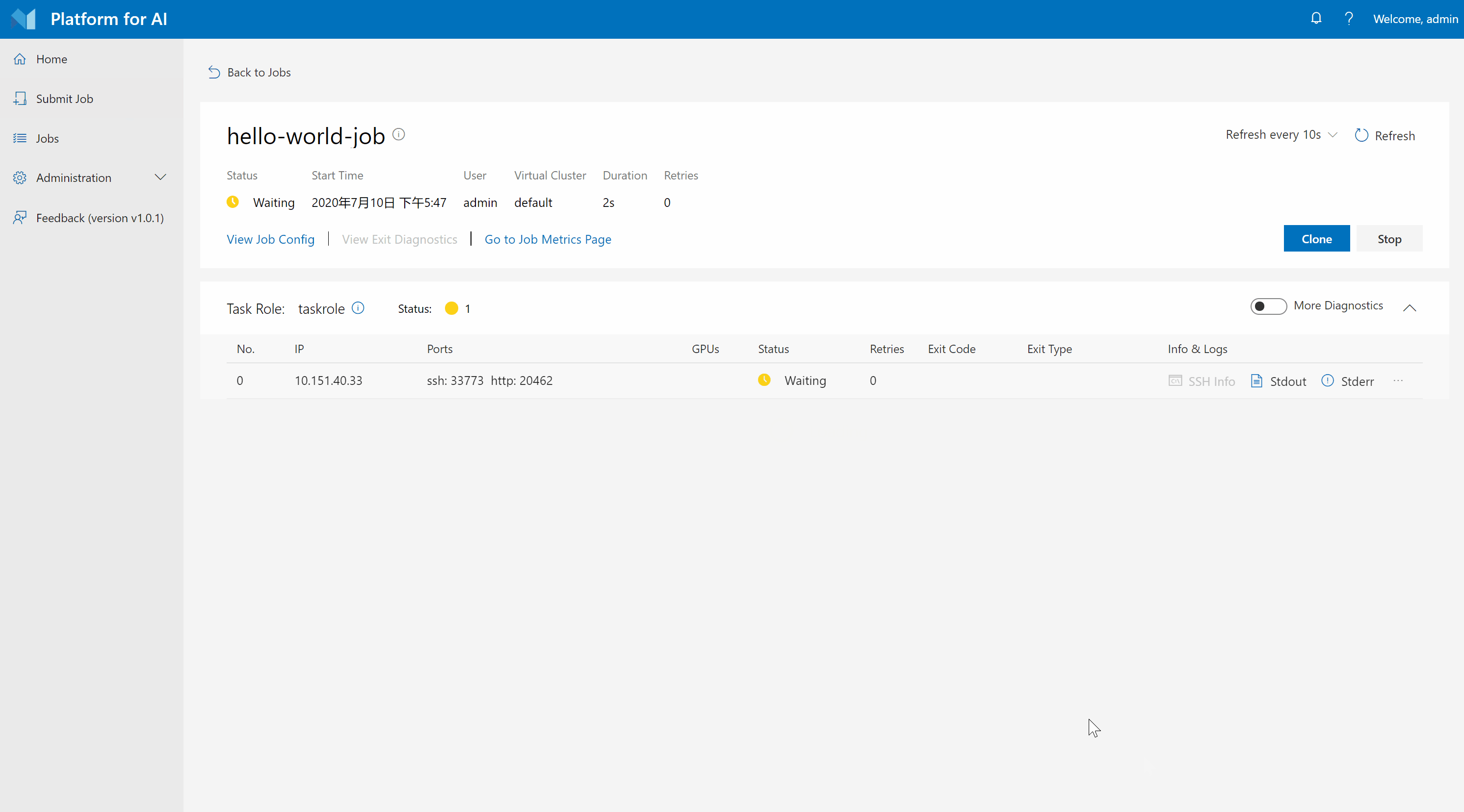
Now your first OpenPAI job has been kicked off!
Browse Stdout, Stderr, Full logs, and Metrics
The hello world job is implemented by TensorFlow. It trains a simple model on the CIFAR-10 dataset for 1,000 steps with downloaded data. You can monitor the job by checking its logs and running metrics on the webportal.
Click the Stdout and Stderr buttons to see the stdout and stderr logs for a job on the job detail page. If you want to see a merged log, you can click ... on the right and then select Stdout + Stderr.
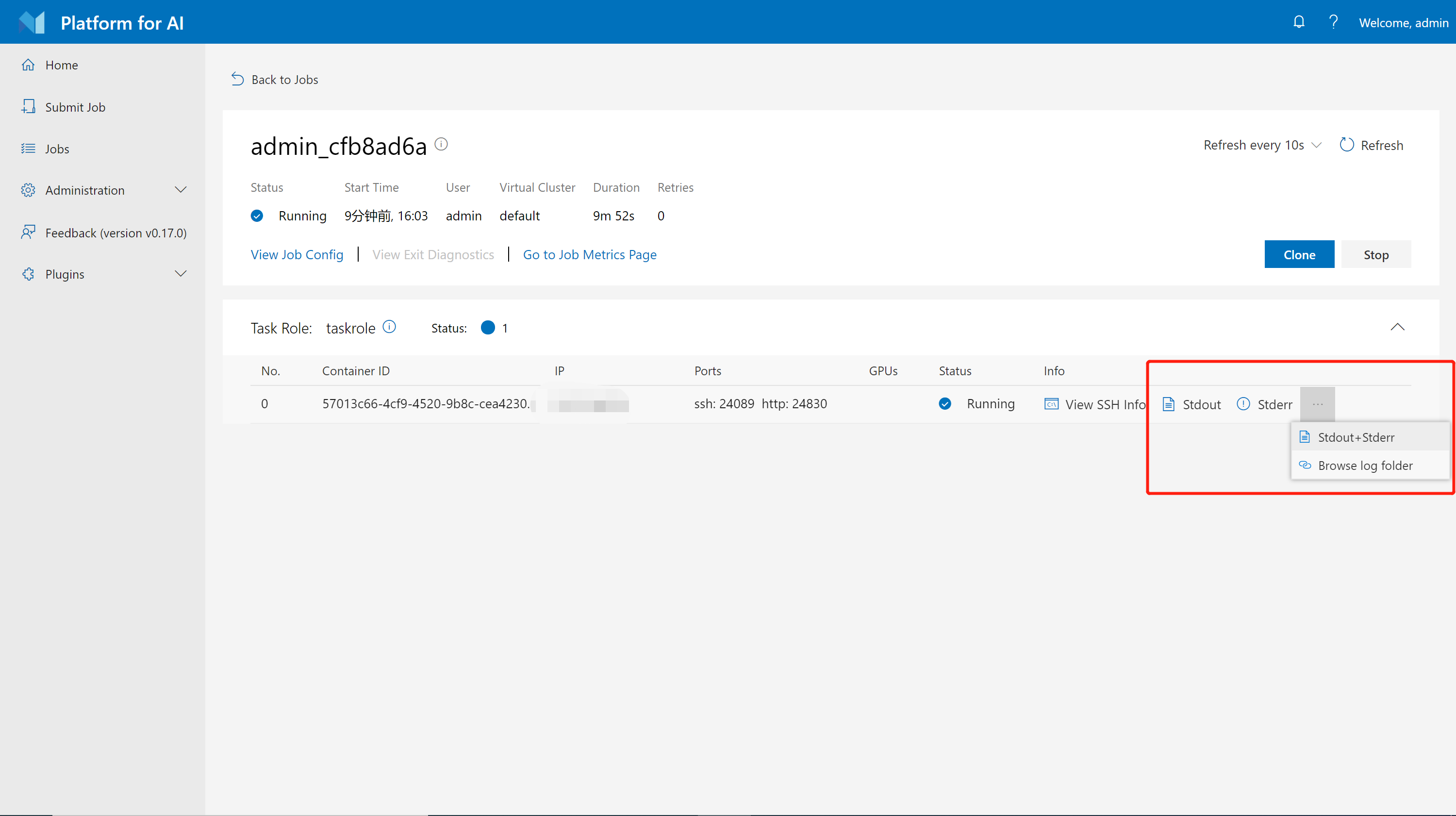
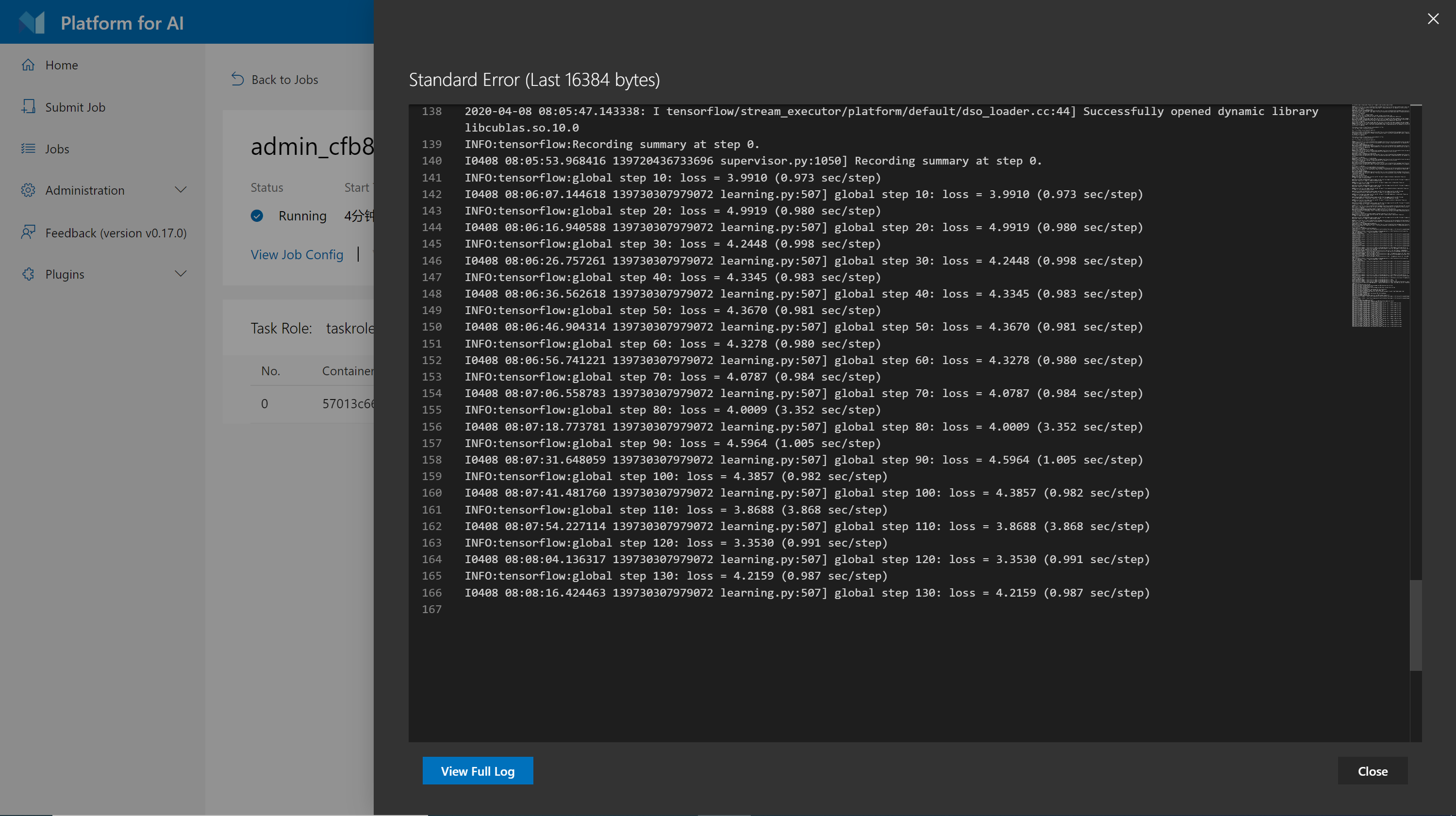
As shown in the following screenshot, we will only show the last 16KB logs in the dialog. Click View Full Log for a full log.
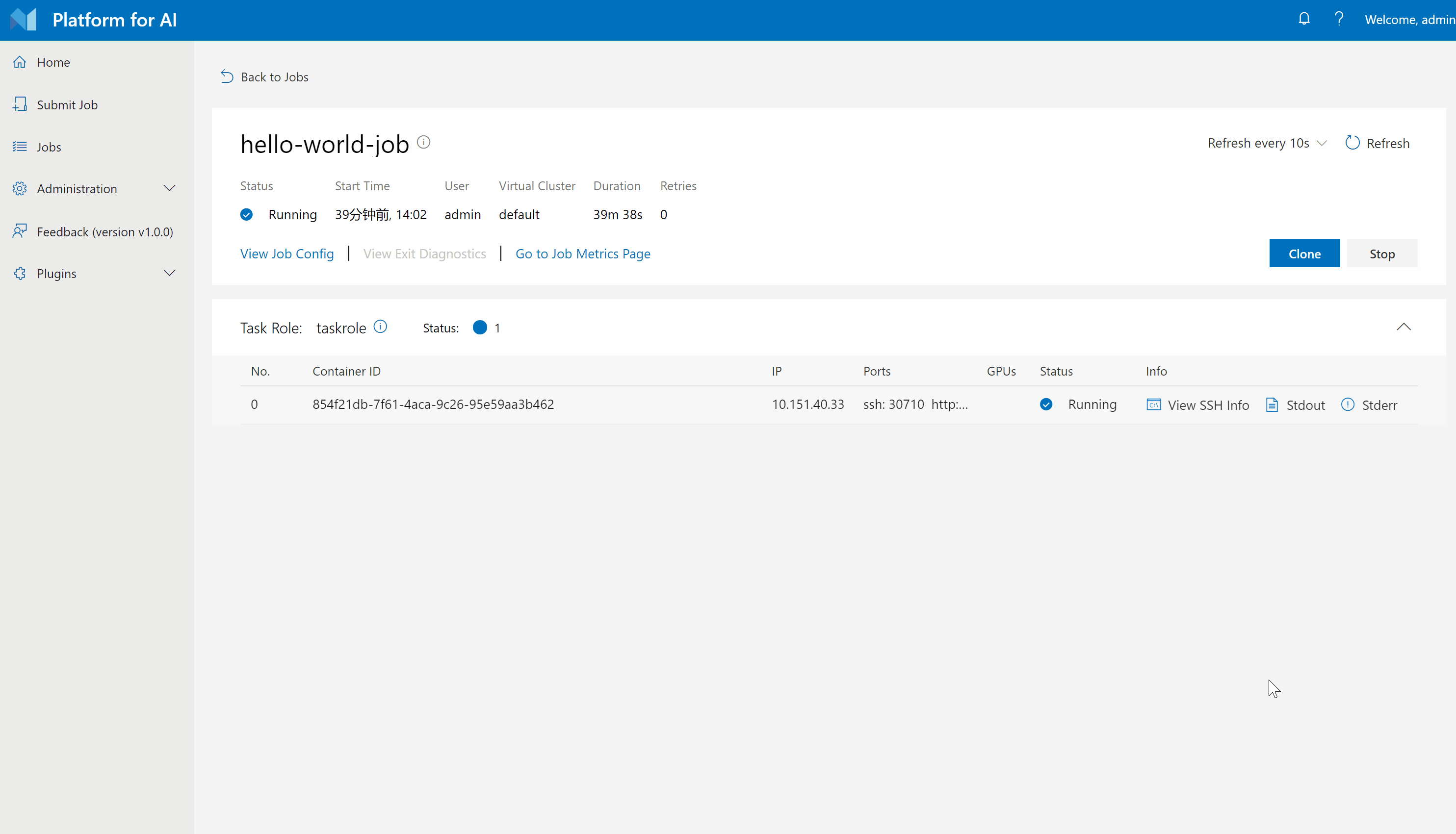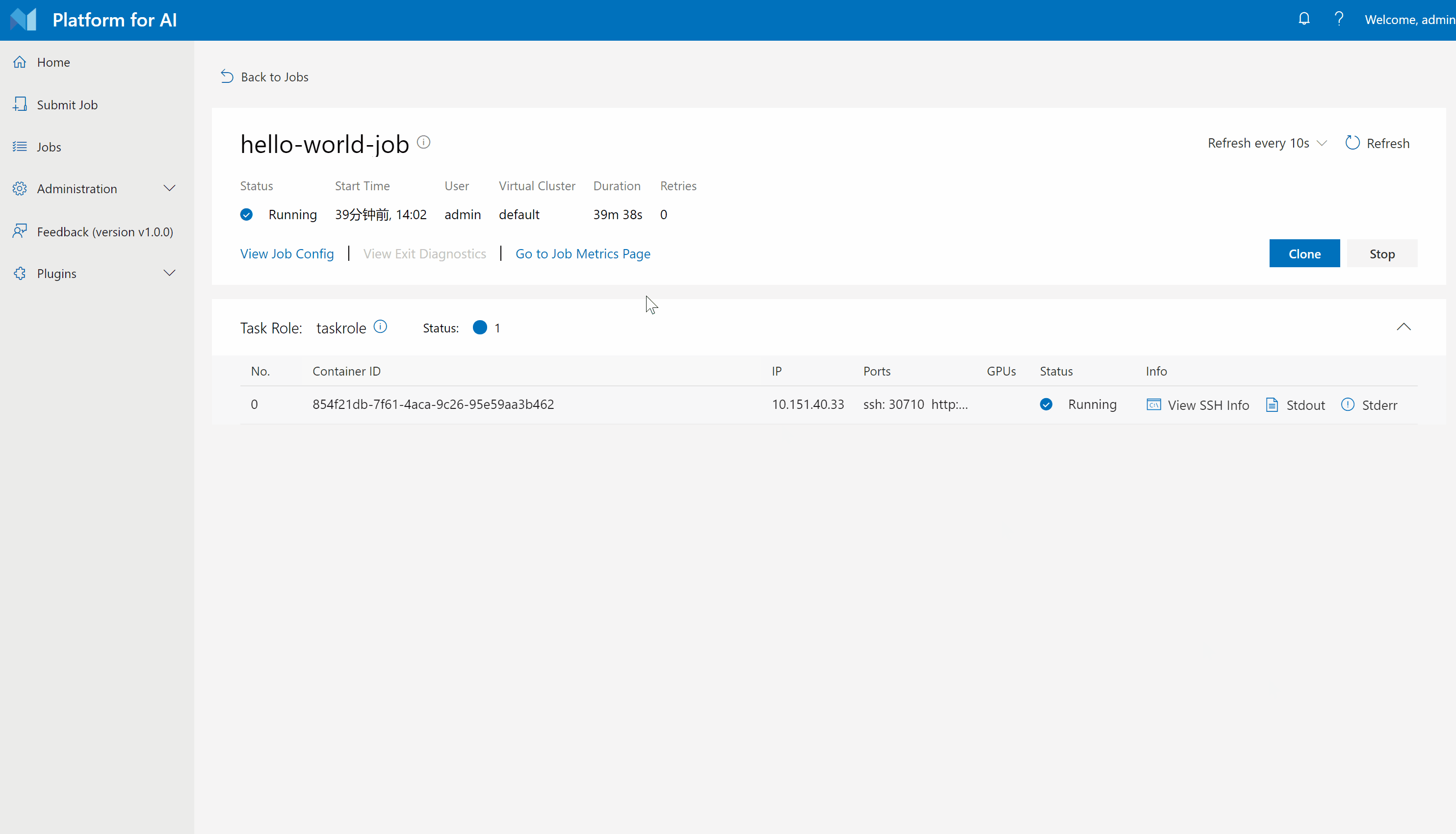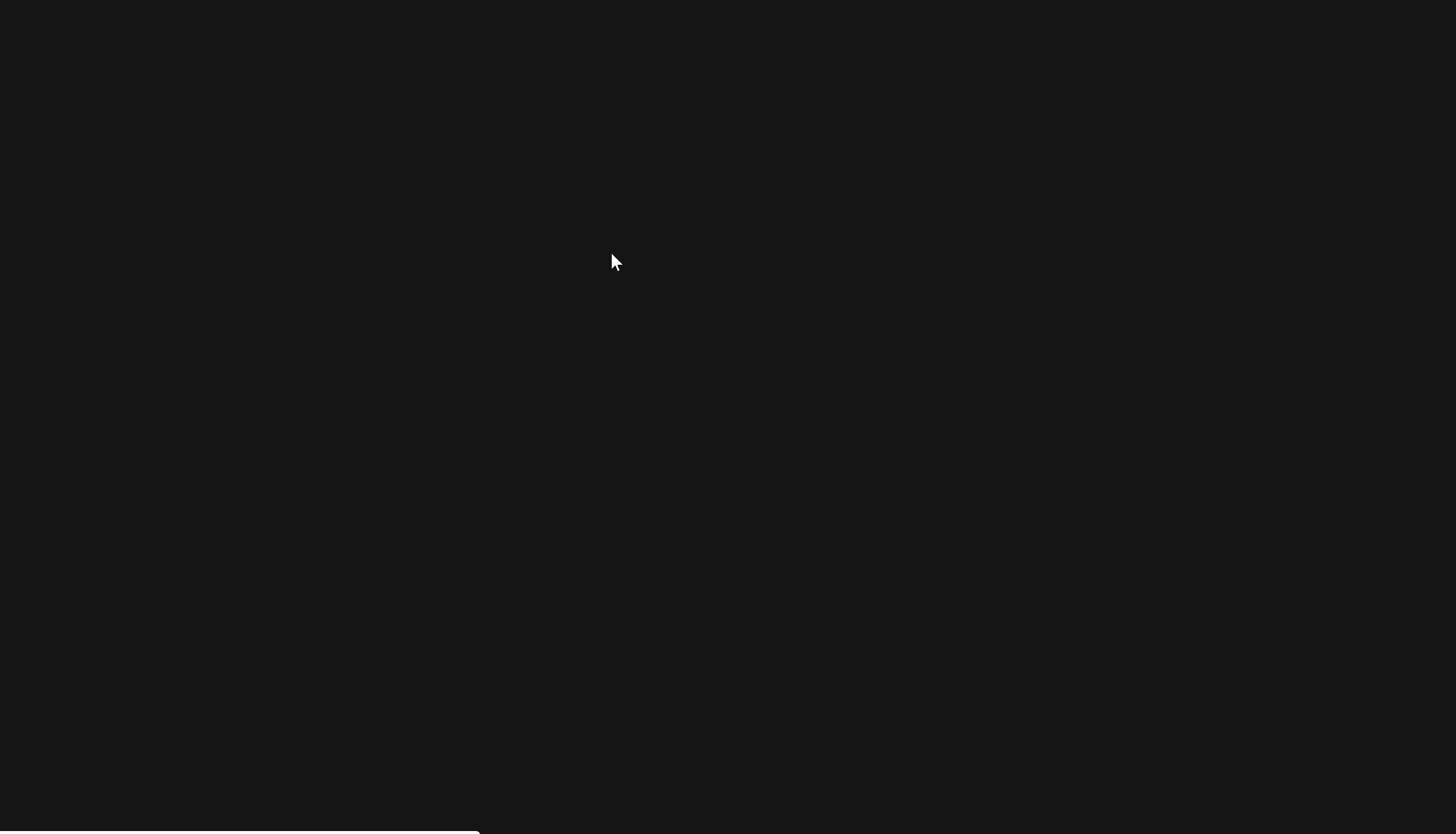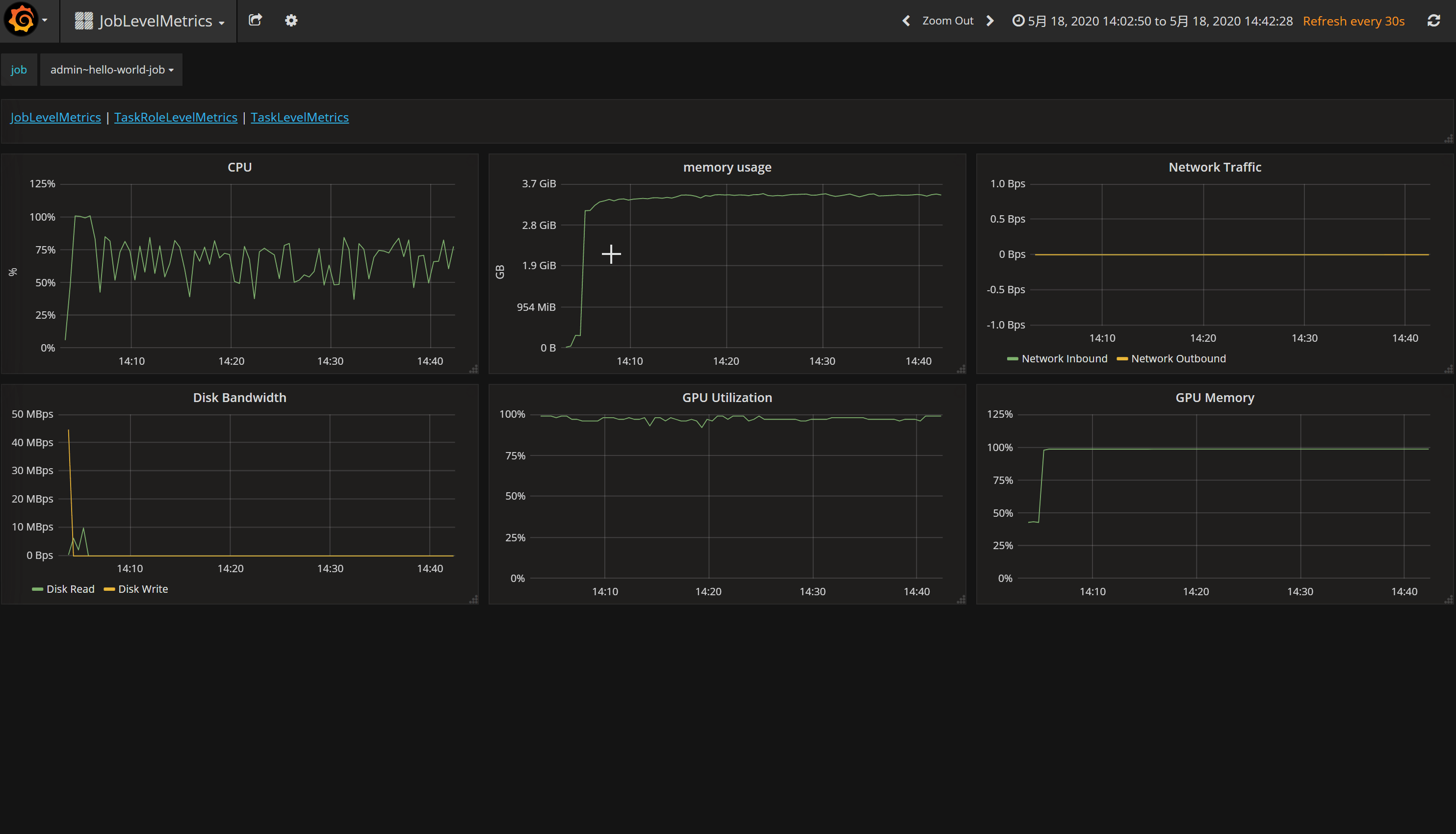
On the job detail page, you can also see metrics by clicking Go to Job Metrics Page. Then the data (including CPU / GPU utilization, network usage, etc.) will be displayed in a new window:
Submit the Hello World Job Step by Step
Instead of importing a job configuration file, you can submit the hello world job directly through the web page. The following is a step-by-step guide:
Step 1. Login to OpenPAI webportal.
Step 2. Click Submit Job on the left pane, then click Single to reach this page.
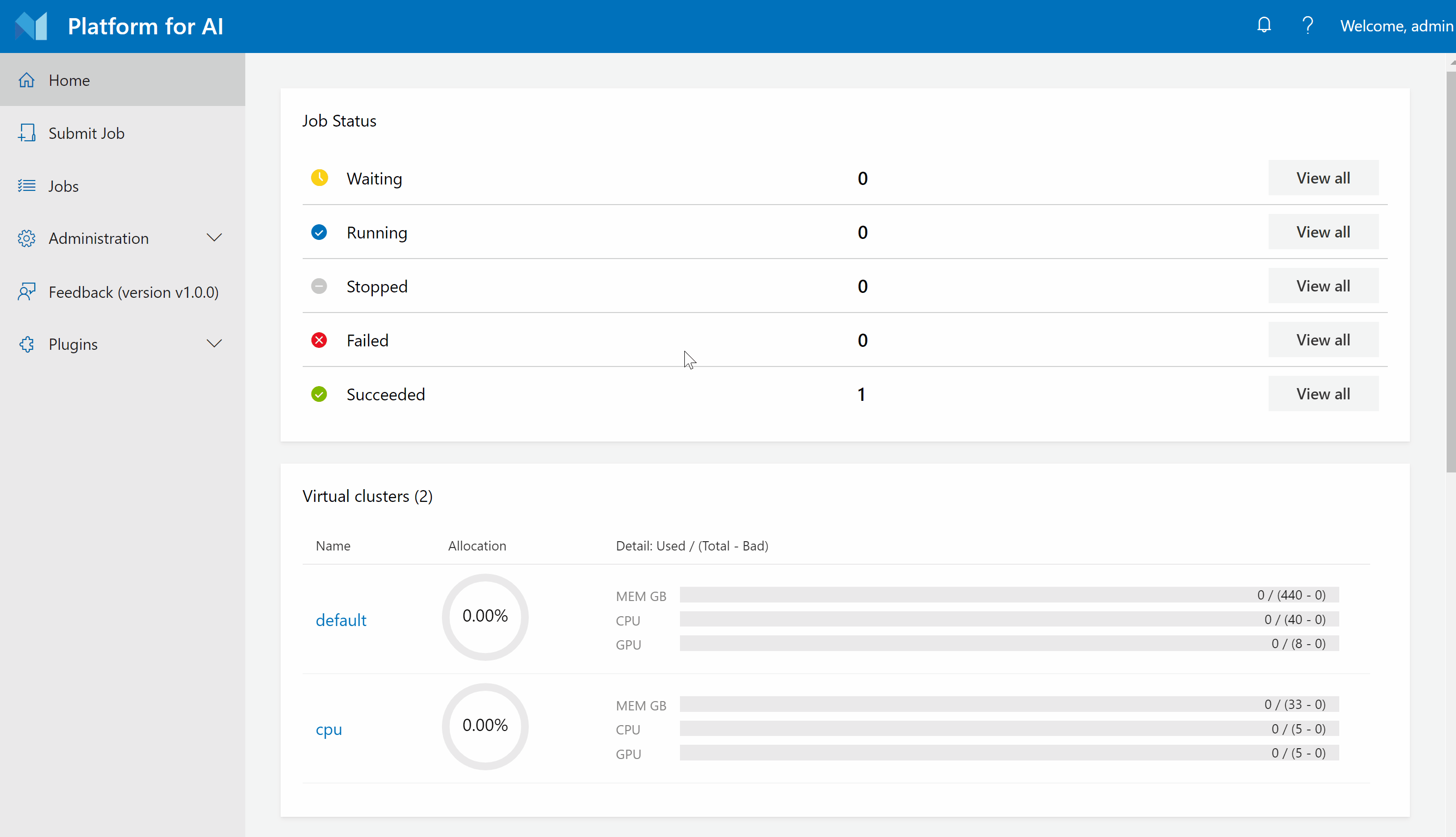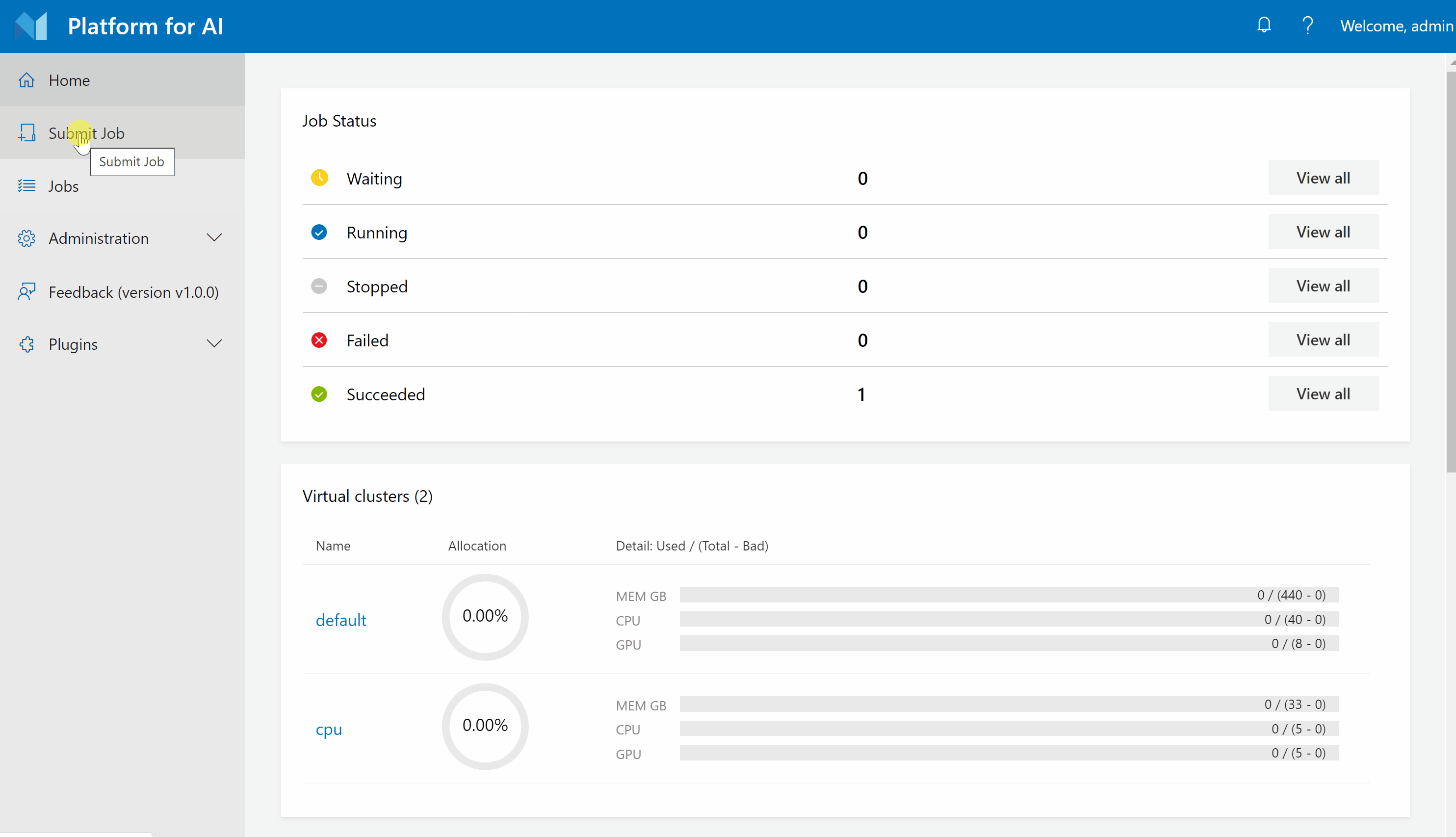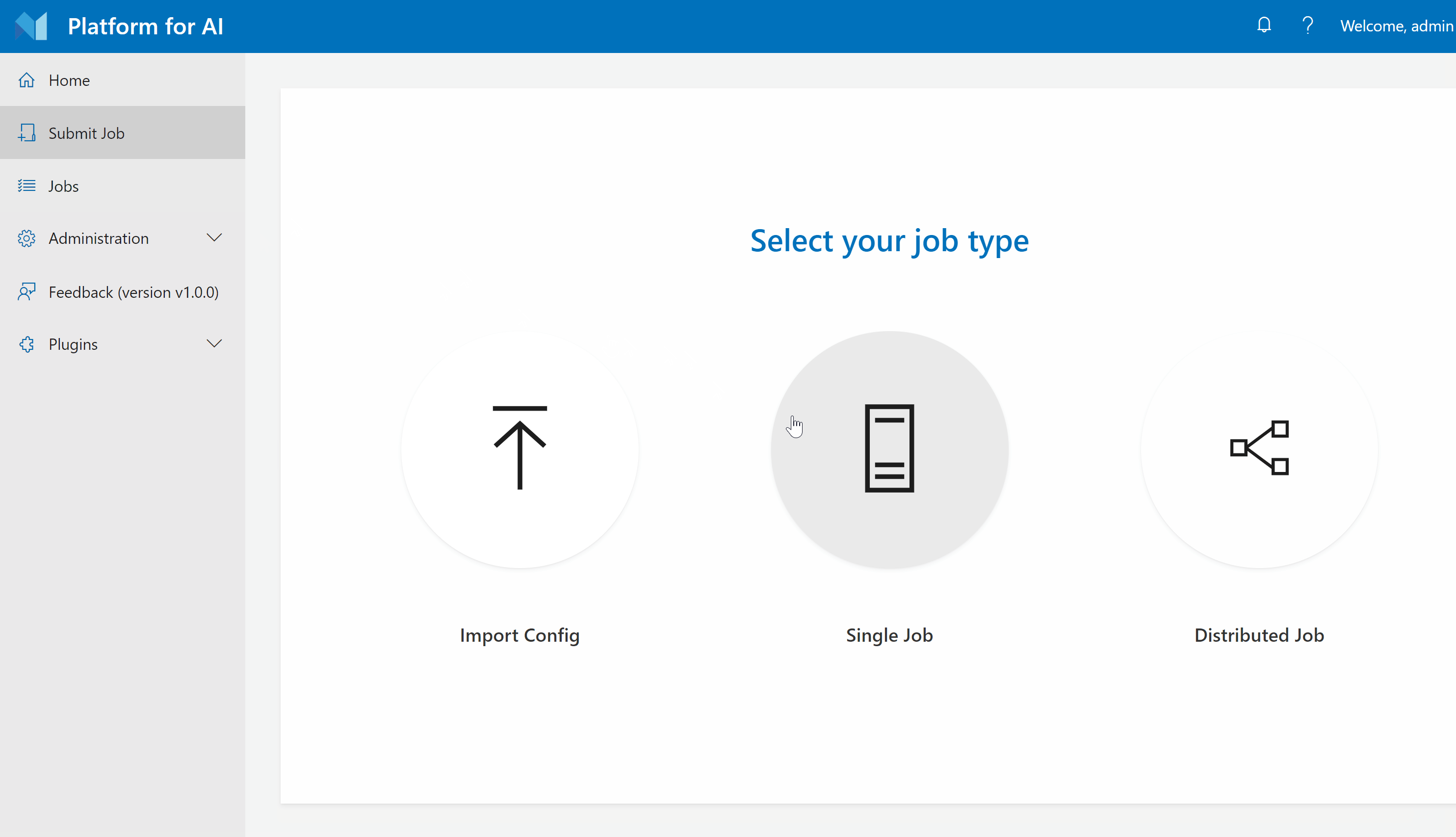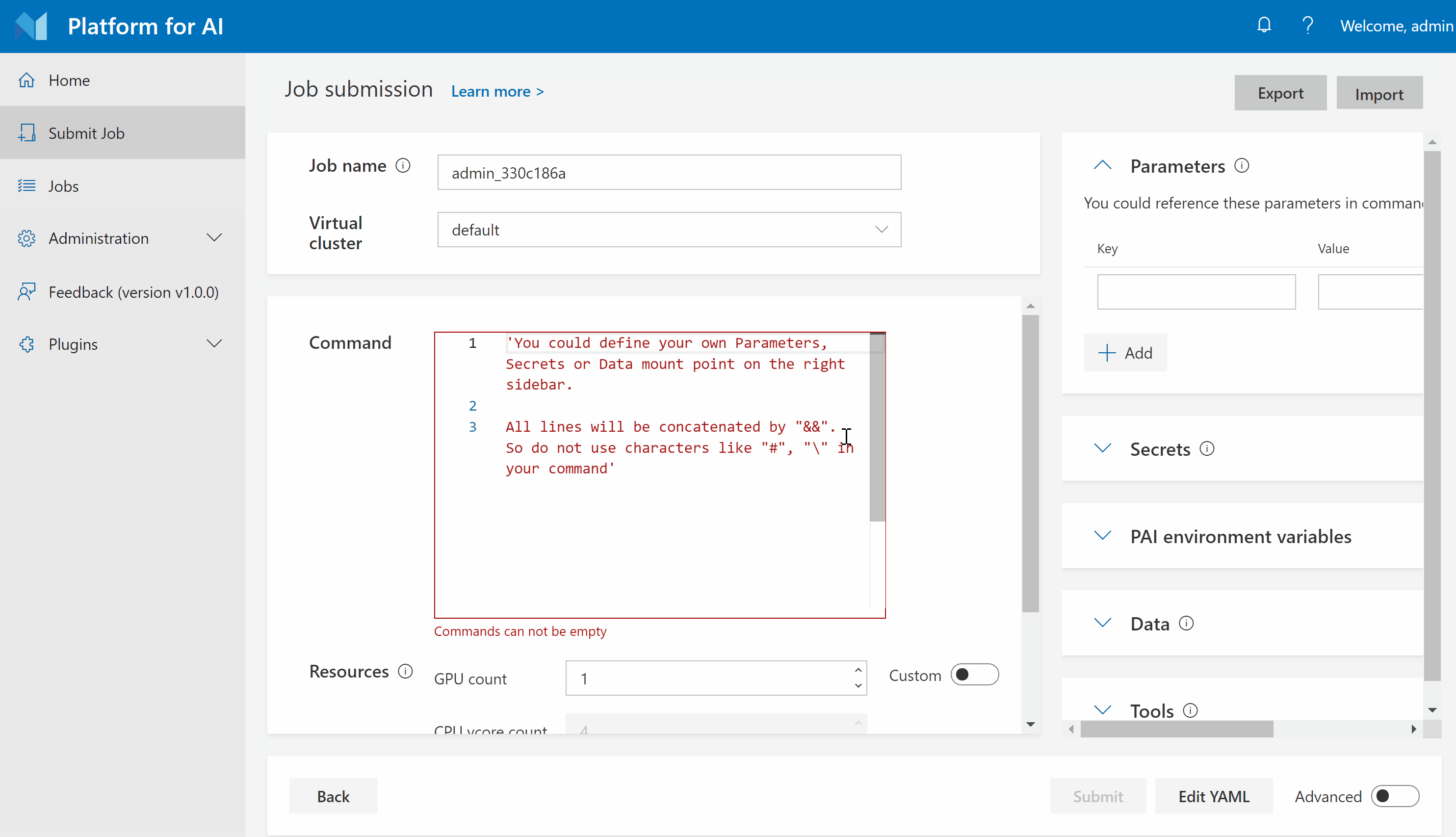
Step 3. Select your virtual cluster, and give a name for your job. Then copy the following commands into the command box.
git clone https://github.com/tensorflow/models
cd models
git reset --hard 62bf6fc0bb2b41a4fb851909c132647a7e0774b0
cd research/slim
python download_and_convert_data.py --dataset_name=cifar10 --dataset_dir=/tmp/data
python train_image_classifier.py --dataset_name=cifar10 --dataset_dir=/tmp/data --max_number_of_steps=1000
Note: Please DO NOT use # for comments or use \ for line continuation in the command box. These symbols may break the syntax and will be supported in the future.
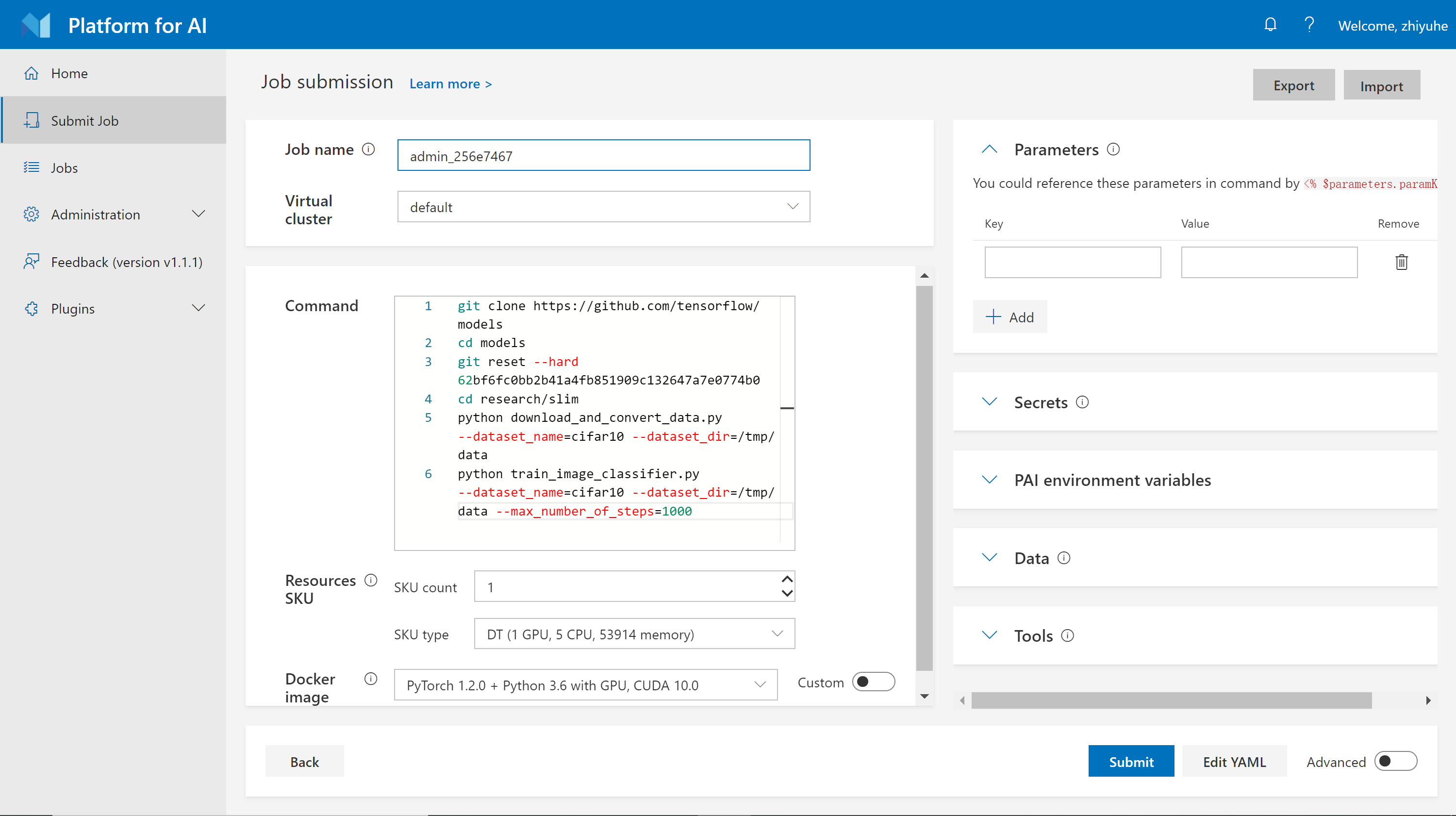
Step 4. Specify the resources you need. OpenPAI uses resource SKU to quantify the resource in one instance. For example, here 1 DT SKU means 1 GPU, 5 CPUs, and 53914 MB memory. If you specify one DT SKU, you will get a container with 1 GPU, 5 CPUs, and 53914 MB memory. If you specify two DT SKUs, you will get a container with 2 GPUs, 10 CPUs, and 107828 MB memory.
Step 5. Specify the Docker image. You can either use the listed docker images or take advantage of your own. Here we select TensorFlow 1.15.0 + Python 3.6 with GPU, CUDA 10.0, which is a pre-built image. We will introduce more about docker images in Docker Images and Job Examples.
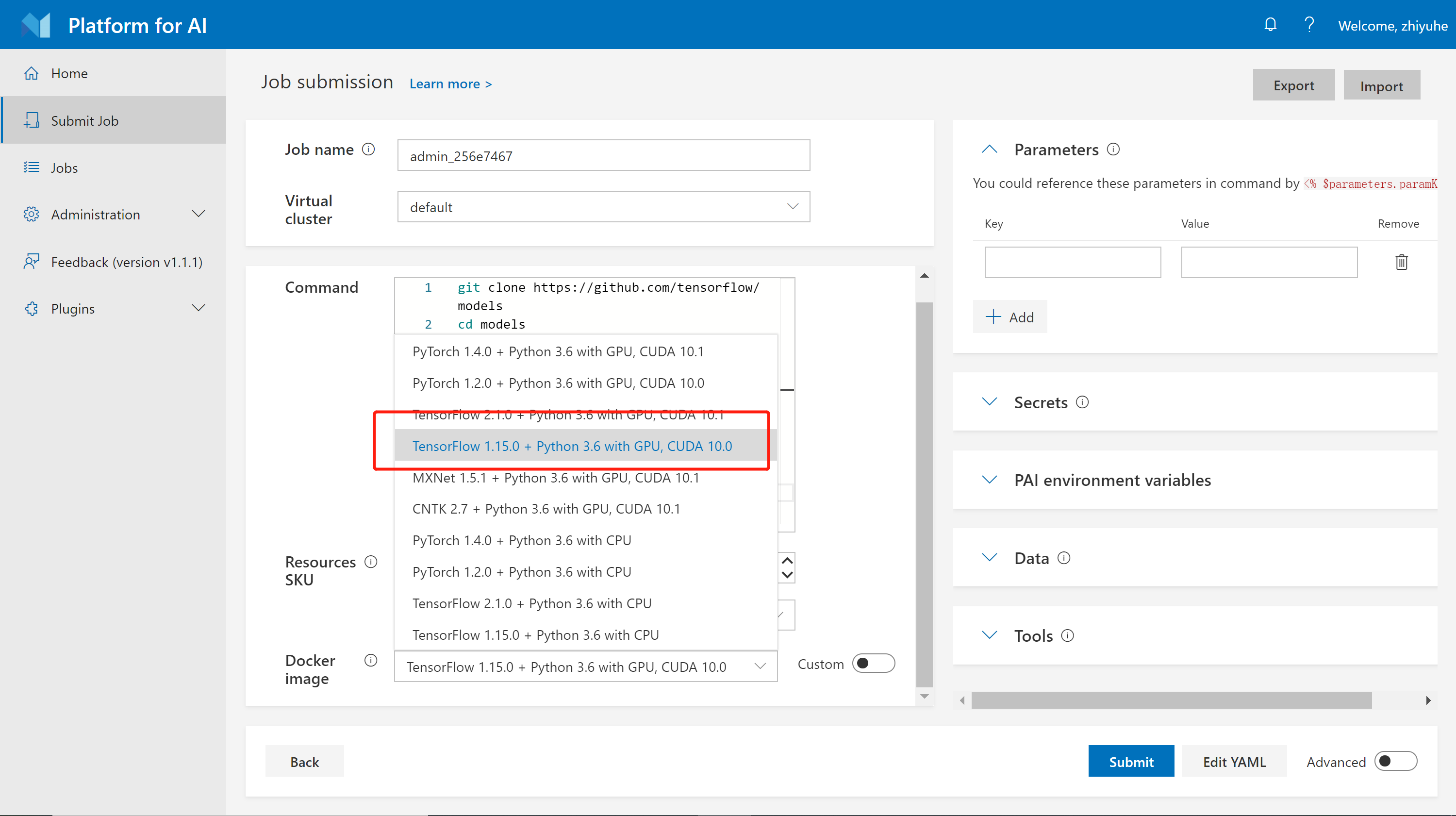
Step 6. Click Submit to submit the job.
Learn the Hello World Job
Here are some detailed explanations about configurations on the submission page:
-
Job name is the name of the current job. It must be unique within all jobs of the same user account. A meaningful name helps manage jobs well.
-
Command is the commands to run in this task role. It can be multiple lines. For example, in the hello-world job, the command clones code from GitHub, downloads data, and then executes the training progress. If one command fails (exits with a nonzero code), the following commands will not be executed. This behavior may be changed in the future.
-
GPU count, CPU vcore count, Memory (MB) are easy to understand. They specify corresponding hardware resources including the number of GPUs, the number of CPU cores, and the amount of memory in MB.
We will introduce more details about the job configuration in How to Use Advanced Job Settings.